Are there tools to create a directory of local business in mediawiki form? Something that would allow the businesses to add their information (company name, address, tags) easily?
Are there any way to filter changes by comment (e.g. changes containing some word)?
I want something similar to meta=query&list=recentchanges api, but with ability to filter changes by comment.
Link a page section in another page – webmasters.stackexchange.com
I want to build a category page, with several categories and 2-3 rows of information for them,
then display the individual sections of this list in other pages (category details, or specific items ...
How do I allow CORS requests on mediawiki? – stackoverflow.com
I tried adding $wgCrossSiteAJAXdomains = array( '*' ); to LocalSettings.php, but didn't work.
I am trying to add content created by an external server. The snippet below shows how I want to show the ...
[MediaWiki-l] EMWCon Spring 2019: registration now open
Registration for the upcoming EMWCon (Enterprise MediaWiki Conference) is
now open! To register, go here:
The cost is $400 if your company or organization is paying for your
attendance, and $100 otherwise. For that price you get two full days of
talks, a "create camp" (hackathon-style) day, free breakfast and lunch on
all three days, plus some fun social events. Really a pretty good deal!
EMWCon will be taking place about six weeks from now, April 3-5, in Daly
City, California. You can read more about it here:
I would like to add some links to external resources displaying in the search results and capturing the search query (i.e. in a similar way as it is done with {{PAGENAME}} in a template). I know about ...
I am trying to update my company's Wiki page to the latest update you have (1.32.0). There is a download file but I need some assistance on how to execute the download. I read through the guide but still a little confused. Is this something you could assist me with?
I contacted another department that directed me here, see referenced [Ticket#2019021810008303]
A new episode of the MediaWiki podcast "Between the Brackets" has been
published: this one is an interview with Barry Grenon, who is Senior
Manager of the Information Experience team at Genesys. We talked about the
use of MediaWiki for documentation and technical communication, which has
what I think is a very nice setup at Genesys. You can hear the episode here:
Been having this problem for months, I just cannot fix it. I have Mediawiki 1.31.1 with PHP 7.1.26 on Apache using Nginx as a reverse proxy
Everything works...
Except when changing configs for short ...
I'm looking for a javascript library or custom solution where I can freely drag drop components and maintain the relationship between them (like which node is connected to what & move the nodes ...
I'm using MediaWiki 1.28 and have a custom extension that relies on a couple of javascript/css libraries hosted on a CDN.
I'm currently loading those libraries using the BeforePageDisplay hook in ...
Get query data from semantic wiki – stackoverflow.com
My wiki pages use semantic wiki to classify all pages. My question is how to query data from semantic wiki from the server side? I need JSON or AJAX data from semantic wiki for my extension.
On page before DOCTYPE not known script – stackoverflow.com
On some pages in MediaWiki, there is an unknown script before the doctype.
</div>
<script type="text/javascript">
setTimeout(function(){var a=document.createElement("script");
var ...
На странице перед DOCTYPE не известный скрипт – ru.stackoverflow.com
На некоторых страницаx в MediaWiki перед доктайпом есть неизвестный скрипт
</div>
<script type="text/javascript">
setTimeout(function(){var a=document.createElement("script");
var ...
Delete old revisions in Mediawiki – stackoverflow.com
I have tried the deleteOldRevisions script, but it kept running for hours without completing the job. I have read relevant questions like this one: How to delete old MediaWiki revisions when ...
I recently found that wikipedia has Wikiprojects that are categorised based on discipline (https://en.wikipedia.org/wiki/Category:WikiProjects_by_discipline). As shown in the link it has 34 ...
Running a mediawiki site at site root?
Published 16 Feb 2019
by /u/psychephylax
on MediaWiki.
I would like set up a virtual machine or a docker image that will let me set up an internal wiki for my household, I have tried to search on how to set it up at the site root rather than as part of a site but only found 1 page that had a debate on whether it was recommended or not and what some use cases for having it at the root were.
I am trying to use this dropdown as a Mediawiki template and allow for Mediawiki parameters in the URL creation (I.e. {{PAGENAME}}). Apparently, this type of html elements is not parsed. Trying $...
mysql_real_escape_string(): Access denied in DB insert – stackoverflow.com
I am trying to use a legacy MediaWiki extension on PHP 5.6 and later versions, and it fails when it comes to DB inserts.
And yes, this is not a duplicate, as the code is different.
The full error ...
How to format monolingual text type SMW properties so accessible to queries without duplication – stackoverflow.com
I'm trying to mark up inline text as being of a specific language.
I've created a Property::Has language page with [[Has type::Monolingual text]].
But when I add [[Has language::(some text)@eo| ]], ...
How to disable automatic linking in recent Mediawiki versions (1.29 and 1.30)? – stackoverflow.com
Newer versions of Mediawiki appear to have this feature where text strings are aggressively converted to links. For example, if you put "File:Foo" on a wiki page, it will be autoconverted to a link, ...
but no working solution has been found. I’m struggling to remove sitelinks to other wikimedia wikis from Wikibase repository:
“Wikipedia
⧼wikibase-sitelinks-wikinews⧽
⧼wikibase-sitelinks-wikiquote⧽
⧼wikibase-sitelinks-wikisource⧽
⧼wikibase-sitelinks-wikivoyage⧽
Other sites”
Any idea ?
Hi,
When you download the CodeEditor extension, you download the whole ACE Editor including loads of languages but by default the extension only let you hightlight css and js files. How to make it hightlight .cs (C#) of other files ?
for my local ( “custom” nginx,mysql ) MediaWiki I want to have the RESTbase running with Parsoid and mobileapps services included. I set up my RESTbase and Parsoid following the instructions [1] [2] and they work fine together.
Now I setup the mobileapps services and tried to include them by roughly following [3] with the main difference, that I did not copy the config.example.wikimedia.yaml but just changed the mobileapps path in the minimal example.yaml used from before.
Now I have a working stand alone mobile apps service but it’s not included into the RESTbase and I have no idea what I’m missing. :-/
I search the documentation but I didn't know exactly how to call that.
I have a template Index2Name that return a name based on an index.
I'm trying to use that name in a link:
[[Articles/{{...
I am getting the following error displayed while trying to edit a page with the aid of Visual Editor (It did not work previously yet):
Error loading data from server: ...
[MediaWiki-l] EMWCon Spring 2019: Call for Presentations
MediaWiki admins, developers, and users: we are excited to bring you EMWCon
Spring 2019, the Enterprise MediaWiki Conference [0], April 3-5 in Daly
City, CA, just outside San Francisco. The conference will have two days of
talks followed by a one day Create Camp. There will be many opportunities
to interact with others using and developing MediaWiki.
To make the best event possible, we need your help! We are looking for
talks that answer any of the following questions:
* Who is using MediaWiki?
From small communities to large organizations, who are the users?
* What is MediaWiki being used for?
Are you maintaining documentation?
Preserving family history?
Collecting best practices?
Mapping genes?
Mapping natural disasters?
* Where is MediaWiki being used?
Do you have a multinational user base?
Or are you in a large city?
Or in a small village with limited network connectivity?
* Why is MediaWiki being used?
What are the features of MediaWiki that make it useful?
* How is MediaWiki being used?
Do you have tips and tricks for managing MediaWiki?
For building extensions?
Do you have favorite or innovative extensions that enhance your wiki?
Do you have challenges or solutions for increasing contributions to
your wikis?
What would help you use MediaWiki more effectively?
Please propose a talk on the event page [1] as soon as possible,
including a title, a brief description, and your name. If your presentation
is accepted, we’ll contact you to get a short abstract of your talk.
Presentations will be recorded and made available after the conference.
Registration for EMWCon is coming soon. To learn more about previous EMWCon
conferences, please see [2].
I am ideally after resizing and setting a maxWidth and maxHeight on all my image uploads to mediawiki.
Having looked through the documentation of various different pages in mediawiki I am unable to ...
I’m currently trying to setup up the mediawiki project on my system and i’m working with the mediawiki installation guide for XAMPP (I’m using an ubuntu 16.04 OS).
During my mediawiki installation, i got the warning that APCu is not installed. Then I downloaded APC-3.1.13 tar file and unzipped it, then went into the directory ran the following commands:
/opt/lampp/bin/phpize
./config
make
running the make command returned an error and terminated the compilation:
/home/prosper/Downloads/APC-3.1.13/apc.c:47:43: fatal error: ext/standard/php_smart_str.h: No such file or directory
compilation terminated.
Makefile:195: recipe for target 'apc.lo' failed
make: *** [apc.lo] Error 1
Please i’d really appreciate ideas on how can i resolve this issue and continue my wikimedia installation.
Short of writing a full skin, is there a recommended way to manipulate
and/or replace the standard (Vector) MediaWiki header and footer?
What I'm specifically looking to do is manipulate the content at the very
top and bottom of the page (aka frame the content), by manipulating the
content and position of specific elements found in the body of the output
(#main-header and #footer). The main header must have links to other
related properties and the footer must have custom disclaimers, copyright
lines etc.
For each concept of my dataset I have stored the corresponding wikipedia categories. For example, consider the following 5 concepts and their corresponding wikipedia categories.
hypertriglyceridemia: ...
$wgResourceModules['zzz.customizations'] = array(
'styles' => "skin.css", // Stylesheet to be loaded in all skins
// Custom styles to apply only to Vector skin. Remove if you don't use it
'skinStyles' => array(
'vector' => 'skin-vector.css',
),
// End custom styles for vector
'scripts' => "skin.js", // Script file to be loaded in all skins
'localBasePath' => "$IP/customizations/",
'remoteBasePath' => "$wgScriptPath/customizations/"
);
function efCustomBeforePageDisplay( &$out, &$skin ) {
$out->addModules( array( 'zzz.customizations' ) );
}
This code shows a custom css that’s loaded only for the vector skin, and another that’s always loaded. I want to do the same with with the javascript, that is load a js file that’s only for the vector skin as will as one that is always loaded.
I see from that documentation (https://www.mediawiki.org/wiki/Manual:$wgResourceModules) that skinScripts is supported, but I don’t know how it would fit into the above code. Could anyone show me how to modify the above code to make that happen? Thanks.
Is it possible to return Wikipedia API data giving a user's edit count or group membership (flag) data for a specific date, rather than for the current time?
Re counts, I'd like to be able to query ...
How can I edit this page? Seems to be an issue with Visual Editor? – stackoverflow.com
I'm trying to edit a page on Gamepedia and I'm getting everything all jumbled up. Have tried on different computers and browsers, but looks the same. However, someone else I talked to said it looks ...
I am creating my first extension which adds a new page called Special:WikiActivity. So far, I have managed to create the page and fill it with HTML content. Now I want to add CSS. I have followed the instructions on this page and looked at the code of other extensions but my CSS is not being applied. Here are some excerpts from my files:
If I open the developer console in Chrome and add the contents of WikiActivity.css to a new style rule, I can confirm that it works. So I know that the styling is being added to my HTML elements and I am using the correct CSS rule. What am I doing incorrectly?
I’m currently trying to write a Mediawiki extension for a custom wiki site which will allow for uploading a file from a wiki page, process it and write the result back to it (e.g. populate a table on that page) .
More specifically, the functionality should be like this:
An upload button shall be present on a normal wiki page, but only if a page has a specific category, e.g. [[Category:Pages with upload button]];
When user presses an “Upload” button, it brings them to an upload dialog/page where they pick a file;
After the file is uploaded, a python script is called which processes the file and writes the result back to a wiki page (from where the upload button was pressed) along with a reference to the page which contains file info (e.g. link to File: info.txt page)
I already have written the draft extension which partly do this functionality (https://github.com/vscam/FileProcess), but it currently has a few problems:
Couldn’t escape from adding changes to core mediawiki code: added minor changes to includes/specials/SpecialUpload.php:
Commented redirection to the file page after uploading (so my extension could redirect me back to the previous page to further populate it with the file processing result)
Link to the file description page (e.g. File: info.txt) is written to a server file. I need to remember this link to further put it to a page from which upload request was called (along with the file processing result)
Still working on how to automatically insert upload button on a wiki page, when it has a specific category;
Using files on mediawiki server to store http links (to the uploaded file and to the page from which upload request was called). So after uploading a file, the extension read these links and goes back to a page where it populates a wiki table: writes reference to the uploaded file and the result of processing this file. I know it’s probably not the best way of doing this logic. I tried to use mediawiki classes. But since php reruns every time when a page is uploaded, I cannot store these links in object parameters.
Would very much appreciate if you could give me a clue or point to some specific documentation (or even similar extensions) regarding how to deal with the aforementioned problems and improve/change this code.
P.S. Please, don’t judge me strictly as I’ve been working with Mediawiki code only for a couple of weeks
I am pretty new in this field but I managed to install and run Mediawiki (1.31.0) and Semantic MediaWiki (2.5.6) with an external provider.
Now I am trying to upgrade to Semantic Mediawiki 3.0 ...
I would like to use Wikipedia API to get event results on a date, not just the list of the event, but the first 3 articles.
Like when I searched March 3rd, the 1st event on the list is like ...
Re: [MediaWiki-l] What's the best way to improve performance, with regard to edit rate
What is your caching setup (e.g. $wgMainCacheType and friends)? Caching
probably has more of an effect on read time than save time, but it will
also have an effect on save time, probably a significant one. If its just
one server, apcu (i.e. CACHE_ACCEL) is probably the easiest to setup.
There's a number of factors that can effect page save time. In many cases
it can depend on what the content of your page edits (e.g. If your edits
have lots of embedded images, 404 handling can result in significant
improvements).
The first step I would suggest would be to do profiling - https://www.mediawiki.org/wiki/Manual:Profiling This will tell you what
part is being slow, and we can give more specific advice based on that
It's not split up (sharded) across servers, a least as far as page and
revision tables go. There is one active master at any given time hat
handles all writes; the current host has 160GB of memory and 10 physical
cores (20 with hyperthreading). The actual revision *content* for all
projects is indeed split up across several servers, in an 'external
storage' cluster. The current server configuration is available at https://noc.wikimedia.org/conf/highlight.php?file=db-eqiad.php
It's another BTB (Between the Brackets) Digest. Sabine Melnicki talks about pitching MediaWiki by not pitching it, Pau Giner plugs the MediaWiki mobile interface, Håkon Wium Lie tells an amusing anecdote about Tim Berners-Lee, Corey Floyd discusses Conway's Law, Daniel Robbins compares Linux distributions and MediaWiki distributions, and more!
I have installed scribunto, but the models are not active, it seems that there is a problem with lua … it is written that lua is not active yet I’ve followed all the steps:
I am currently using the following code to obtain the page content of wikipedia.
import pywikibot as pw
page = pw.Page(pw.Site('en'), 'Forensic science')
page.text
However, it seems like the above ...
How to identify wikipedia categories in python – stackoverflow.com
I am currently using pywikibot to obtain the categories of a given wikipedia page (e.g., support-vector machine) as follows.
import pywikibot as pw
print([i.title() for i in ...
Real-world example for watchlist feed/watchlist token?
I’m currently updating the documentation for API:Watchlist Feed, and I was wondering if anyone had concrete examples of sharing a watchlist token so another person can access their watchlist feed.
The current page includes code for doing so, which I want to include if possible, but I also want to provide an example. I am also not sure if watchlist tokens are actually being shared by users in this way, or if it makes sense to.
So I want something where I can easily look up things like algorithms (with pseudo code), cheatsheets for app keyboard shortcuts and things like markdown, and short fast rules for things like ...
ManiNerd - Professional Blog Post's
Published 4 Feb 2019
by /u/Fairy_Malik
on MediaWiki.
There was such a problem, I have been suffering for a couple of days, I am still quite a novice.
Using the GET request to the Wikipedia API, I get this object
It turns out that for the pages object, ...
I need to check if a link pasted by a user is actually a link to a wikipedia article about a movie. I was able to check if the link is a valid Wikipedia article so far, but how do I know it is about a ...
Using an extension to access external data using API that requires Authentication: Bearer token
Published 31 Jan 2019
by /u/xx_yaroz_xx
on MediaWiki.
Good evening. I was wondering if there are any extensions available to get data from an external site, to present into MediaWiki? I looked at External Data, but didn't find any way to put the token in there. I did find plugin for DokuWiki that I will be taking a look at tomorrow to see if I can rework it to do what I want.
Is there an easy way to see why a module is being loaded as a dependecy? So for example module “X” is never loaded by OutputPage:addModules / OutputPage:addModuleScripts or mw.loader.using (or similar). But still it is loaded on every page request. Therefore some other module must require it as a dependency.
Are there any debug logs/tools that could help me to find such a dependency?
Hi everyone. I have made a native GTK+ Wikidata Editor called Daty thanks to a sponsorship by Wikimedia CH. At the moment I am being hosted by GNOME project due to similar points of view. In any case, should the project have a project page for bug report or something else on phabricator?
Hi alltogether,
I hope this is the correct mailing list, please excuse if it is not (and
excuse my English, please).
I run a private Wiki and I am trying to create an extension where the user
can enter the title and some content in a form, similar to the extension
InputBox https://www.mediawiki.org/wiki/Extension:InputBox (you cannot enter
page content into the form created by this extension).
I studied the code of several extensions and created something like this:
#*** begin code ***
$pageTitleText = "my new wikipage";
$pageTitle = Title::newFromText( $pageTitleText );
$pageContentText = "my new page content";
$pageContent = new WikitextContent( $pageContentText );
$newWikiPage->doEditContent( $pageContent, $pageContent, EDIT_NEW );
#*** end code ***
Actually this is not working and creates an internal error.
I tried something different
#*** begin code ***
#...
$me = User::newFromSession();
$newWikiPage->doCreate($pageContent,EDIT_NEW,$me,"summary",array());
#*** end code ***
This code creates an internal error, too. array() should be an array with
meta-information which I could not figure out until now.
I have studied the internal documentian https://doc.wikimedia.org/mediawiki-core/REL1_31/php/ and the code of
several exentions, and now I am lost in classes and PHP-Code, maybe someone
can help me out?
Thank you for reading this,
Manuela
I am slightly embarrassed to ask this but I am a total web dev noob and after a lot of searching online I still can't figure out how to deploy the most basic template for a "Note" template as seen here. <https://www.mediawiki.org/wiki/Template:Note>
All the docs I can find talk about writing your own templates or exporting/importing them from other pages etc.
Is this actually required to get simple note box going like the examples on the above page (coloured box with simple icon)?
I would have thought this sort of basic stuff is included in the default installation but clearly I am missing something.
I am working on a tool to facilitate patrolling of recent changes, and part of the tool’s user interface consists of a big <iframe> showing the current state of a page by embedding Special:PermaLink/id. Most of the time, this works fine; however, if the page was recently created by a new contributor, and the tool user is logged in on the wiki I am embedding, then MediaWiki will show a ”mark page as patrolled” link, and to protect that link against clickjacking, it will also send an X-Frame-Options: DENY header, rendering my tool’s <iframe> blank.
Is there anything I can do about this? I don’t need the “mark as patrolled” link on the page, for all I care the page might as well be loaded without the user being logged in at all. Perhaps there’s some kind of URL parameter to tell MediaWiki to ignore the user’s cookies (and pretend the wiki is read-only, to prevent the user from revealing their IP if they edit, I suppose)? Or does anyone have other ideas?
One thing I could do (and in fact considered doing in the past, when I was embedding diff pages instead of view pages) is to download the page server-side (in my tool) and then serve it to the user from my tool… but that’s feels like a pretty ugly hack.
When I click on login, I see a dialog with three buttons: Phab, Github, email. If I click on email I get the error message Please enter your email or username. but I don’t see anything it could be entered into.
Disabling email login is fine IMO, but the current halfway state is confusing.
Sorry if this is a dumb noob question. I'm familiar with *nix systems, but this is my first time hosting a wiki. That said, my wiki is hosted on a shared VPS, and as such, I don't have root access. I've been reading through the mediawiki docs and I'm getting the impression that it's safe, as long as you configure the server correctly. I've seen references to files such as /etc/php.ini which need to be configured correctly to ensure users cannot upload malicious scripts, but as I can't use "sudo" I can't even read the file--much less modify it--to make sure everything's good before enabling user uploads.
Is there a way around this that doesn't require sudo?
Am I misunderstanding the docs/overthinking this?
Any other security matters I should be aware of before enabling uploads?
Megan Cutrofello, also known as "River", is the manager of Leaguepedia and other esports wikis at the website Gamepedia. She has been involved with esports wikis since 2014.
I have been tasked with upgrading our mediawiki installation. Here's the rub, apparently we are on version 1.14 (2009). When you get your breath back after laughing, if anyone has a ball-park guesstimate as to if this is even possible, I would be interested in hearing people's opinions. I can do the research for upgrading, but this looks like a Herculean task at this point to go through 10 years worth of upgrades to get to a current version. There must be shortcuts but I don't see them. Any ideas would help, even if the idea is throw away the old installation and start a new with a current version, it's something I can run up the org charts.
Ubuntu Trusty was released in April 2014, and support for it (including security updates) will cease in April 2019. We need to shut down all Trusty hosts before the end of support date to ensure that Toolforge remains a secure platform. This migration will take several months because many people still use the Trusty hosts and our users are working on tools in their spare time.
2019-01-11: Availability of Debian Stretch grid announced to community
Week of 2019-02-04: Weekly reminders via email to tool maintainers for tools still running on Trusty
Week of 2019-03-04:
Daily reminders via email to tool maintainers for tools still running on Trusty
Switch login.tools.wmflabs.org to point to Stretch bastion
Week of 2019-03-18: Evaluate migration status and formulate plan for final shutdown of Trusty grid
Week of 2019-03-25: Shutdown Trusty grid
What is changing?
New job grid running Son of Grid Engine on Debian Stretch instances
New limits on concurrent job execution and job submission by a single tool
New bastion hosts running Debian Stretch with connectivity to the new job grid
New versions of PHP, Python2, Python3, and other language runtimes
New versions of various support libraries
What should I do?
Some of you will remember the Ubuntu Precise deprecation from 2016-2017. This time the process is similar, but slightly different. We were unable to build a single grid engine cluster that mixed both the old Trusty hosts and the new Debian Stretch hosts. That means that moving your jobs from one grid to the the other is a bit more complicated than it was the last time.
The cloud-services-team has created the News/Toolforge Trusty deprecation page on wikitech.wikimedia.org to document basic steps needed to move webservices, cron jobs, and continuous jobs from the old Trusty grid to the new Stretch grid. That page also provides more details on the language runtime and library version changes and will provide answers to common problems people encounter as we find them. If the answer to your problem isn't on the wiki, ask for help in the #wikimedia-cloud IRC channel or file a bug in Phabricator.
See also
News/Toolforge Trusty deprecation on Wikitech for full details including links to tools that will help us monitor the migration of jobs to the new grid and help with common problems
Denny Vrandečić is the co-creator of Semantic MediaWiki and the main creator of Wikidata. He also served on the Wikimedia Foundation board from 2015 to 2016. Since 2015, he has been an ontologist at Google, working on the Google Knowledge Graph, among other projects.
Is there an SQL importer that works with MediaWiki 1.27 or newer? I have tried using mwdumper, but the generated SQL gives me errors when trying to import.
Starting 2019-01-03, GET and HEAD requests to http://tools.wmflabs.org will receive a 301 redirect to https://tools.wmflabs.org. This change should be transparent to most visitors. Some webservices may need to be updated to use explicit https:// or protocol relative URLs for stylesheets, images, JavaScript, and other content that is rendered as part of the pages they serve to their visitors.
Three and a half years ago @yuvipanda created T102367: Migrate tools.wmflabs.org to https only (and set HSTS) about making this change. Fifteen months ago a change was made to the 'admin' tool that serves the landing page for tools.wmflabs.org so that it performs an http to https redirect and sets a Strict-Transport-Security: max-age:86400 header in its response. This header instructs modern web browsers to remember to use https instead of http when talking to tools.wmflabs.org for the next 24 hours. Since that change there have been no known reports of tools breaking.
The new step we are taking now is to make this same redirect and set the same header for all visits to tools.wmflabs.org where it is safe to redirect the visitor. As mentioned in the lead paragraph, there may be some tools that this will break due to the use of hard coded http://... URLs in the pages they serve. Because of the HSTS header covering tools.wmflabs.org, this breakage should be limited to resources that are loaded from external domains.
Fixing tools should be relatively simple. Hardcoded URLs can be updated to be either protocol relative (http://example.org ➜ //example.org) or explicitly use the https protocol (http://example.org ➜ https://example.org). The proxy server also sends an X-Forwarded-Proto: https header to the tool's webservice which can be detected and used to switch to generating https links. Many common web application frameworks have support for this already:
If you need some help figuring out how to fix your own tool's output, or to report a tool that needs to be updated, join us in the #wikimedia-cloud IRC channel.
Why does Simple MathJax Break my mediawiki?
Published 31 Dec 2018
by /u/freezodaz
on MediaWiki.
Download and place the file(s) in a directory called SimpleMathJax in your extensions/ folder.
Add the following code at the bottom of your LocalSettings.php: wfLoadExtension( 'SimpleMathJax' ); [Adding this text breaks the mediawiki so only a white screen shows.]
Yes Done – Navigate to Special:Version on your wiki to verify that the extension is successfully installed.
I'm the adminstrator of PlexodusWiki, coordinating information on migrating users from Google+ and other closed / dying social networks.
We're trying to organise a few larger chunks of information which are somewhat unwieldy in a traditional free-text wiki format, including:
Descriptions of various user-generated and social media formats.
Descriptions and comparisions of ~250+ social media platforms.
Several "notable names" databases of users and communities, which might range into the 100s or 1,000s of entries.
Potentially listing signficant portions of federated or decentralised networks which might have 100s or 1,000s, or more, instances.
Drawing or referencing information from third-party sources, including automated reporting systems.
I'm familiar with basic MediaWiki formatting, tables, etc. I've been looking into templates. I'm searching for other tools, approaches, things to do, things to avoid.
While we're not aiming to build a structured database, there are parts of this that might end up looking like that. Ways to deal with data and text entry, repetitive formats, some structure but also the ability to change and adapt that, would all be useful.
Questions:
Are we using the right tool for the right job?
Are there any examples of similar-sounding projects (or sections of, say, Wikipedia) people could point us to?
What are good concepts to keep in mind for content organisation of this sort?
What should we do?
What should we avoid doing?
What sorts of tools exist for automating/assisting in this?
What kinds of "philosophy of mediawiki" guides might be useful, if an exist?
What kinds of "technical engineering of mediawiki" guides might be useful?
I feel like I'm diving off the deep end on much of this, I'd like to avoid painful and time-consuming mistakes.
Daniel Robbins is the creator of the Linux distributions Gentoo Linux and Funtoo Linux; he remains in charge of Funtoo Linux. He also runs the consulting company BreezyOps, which does consulting on a wide variety of open-source software, including Linux and MediaWiki.
I find tables tricky to do in wiki markup and my wiki is on a shared host so I can’t add VisualEditor so what are some ways to create and edit wiki tables WISYWIG-style? Is there a wiki editor I can download and run on my MacBook since I can’t get VisualEditor to work in my browser?
Hi, I wonder if anyone can advise me. I have an old PC running Ubuntu Server which has died. It had a copy of Mediawiki on it, containing location data for sites on a private Minecraft server. I'd like to recover that data.
Can anyone tell me how I can get the content of the relevant Mediawiki pages off the old server in a useable form? I'm fine with accessing the hard disk. It's locating the Mediawiki contents that's giving me a headache.
Håkon Wium Lie is best known as the inventor of CSS. He also served as the CTO of Opera Software, makers of the Opera browser, and has been involved in a number of other ventures, web-related and otherwise. Since the beginning of 2018, he has served as the public face of the MediaWiki-based website Rettspraksis.no, which holds a directory of the rulings of the Supreme Court of Norway. Due to a lawsuit against Rettspraksis.no (recently concluded), he has become somewhat of an open-data activist as well.
I stood up mediawiki 1.31.1 on an offline network, and was unsure if it was possible to include the (Help Contents) section of the mediawiki for offline use? Can I download it? Or is their a module for it?
Highlights from episodes 12 to 17: it's another BTB Digest! Hear Stas Malyshev defending PHP, Remco de Boer talking about how his consulting practice has expanded, Dustin Phillips talking about the use of MediaWiki at ICANNWiki, Nikhil Kumar and Yashdeep Thorat sharing their thoughts about the Google Summer of Code, and Bartosz Dziewoński praising the OOjs and OOUI JavaScript libraries.
Pau Giner is a user experience (UX) designer who works for the Wikimedia Foundation in the Audiences Design group. He has worked for the WMF since 2012.
We are using Mediawiki version 1.25.2 and would like to avoid upgrading if possible.
In order to upgrade other software on our server, we would need to upgrade from php 5.6 to php 7.2.
I know that php 7.2 is not officially supported for this version of Mediawiki, but the compatibility page says that for 7.1, it generates errors but would probably work. I'm wondering if that's also the case for 7.2.
Sabine Melnicki is a MediaWiki and web consultant based in Vienna, Austria, who does consulting via the brands WikiAhoi and WebAhoi. She has been doing MediaWiki consulting since 2014.
I'm looking for a walkthrough for updating a MediaWiki installation that is set to Private mode, which will allow the update to happen without making the wiki public at any point.
Please create a way for Money Button to be used to create accounts on MediaWiki installations. Think MediaWiki membership sites using Money button. If there is advertising on the site, then members paying with Bitcoin (Cash) won’t see ads. 🙃
Published 29 Sep 2018
by /u/MichaelTen
on MediaWiki.
Please create a way for Money Button to be used to create accounts on MediaWiki installations. Think MediaWiki membership sites using Money button. If there is advertising on the site, then members paying with Bitcoin (Cash) won’t see ads.
Can MediaWiki be developed in such a way as to be as easily upgraded as WordPress? Can MediaWiki Extensions be as easy to install as plugins are in WordPress? These can be eventual features.
Published 28 Sep 2018
by /u/MichaelTen
on MediaWiki.
Can MediaWiki be developed in such a way as to be as easily upgraded as WordPress? Can MediaWiki Extensions be as easy to install as plugins are in WordPress? These can be eventual features.
As promised in an earlier post (Blog Post: Neutron is (finally) coming), we've started moving a few projects on our Cloud-VPS service into a new OpenStack region that is using Neutron for its software-defined networking layer. It's going pretty well! The new region, 'eqiad1', is currently very small, and growth is currently blocked by hardware issues (see T199125 for details) but we hope to resolve that issue soon.
Once we have some more hardware allocated to the eqiad1 region we will start migrating projects in earnest. Here's what that will look like for each project as it is migrated:
A warning email about impending migrations will be sent to the cloud-announce mailing list at least 7 days before migration.
On the day of the migration: Instance creation for each migrating project will be disabled in the legacy 'eqiad' region. This means that Horizon will still show instances in eqiad, but creation of new instances will be disabled there.
The current project quotas will be copied over from eqiad to eqiad1.
Security groups will be copied from eqiad to eqiad1, and some rules (those that refer to 10.0.0.0/8 or 'all VMs everywhere') will be duplicated to include the new IP range in eqiad1.
Then, the following will happen to each instance:
The instance will be shut down
A new shadow instance will be created in eqiad1 with the same name but a new IP address or addresses.
The contents of the eqiad instance will be copied into the new instance. This step could take several hours, depending on the size of the instance.
Any DNS records or proxies that pointed to the old instance will be updated to point at the new instance.
The new instance will be started up, and then rebooted once for good measure.
Once the new instance is confirmed up and reachable, the old instance will be deleted.
You will want to check some things afterwards. In particular:
Verify that any external-facing services supported by your project are still working. If they need to be started, start them. If something drastic is happening, notify WMCS staff on IRC (#wikimedia-cloud)
In some cases you may need to restart services if they're unable to restart themselves after a system reboot. For example, Wikimedia-Vagrant seems to usually have this problem.
If you would like an early jump on migration, we have space to move a few projects now. In particular, if you would like access to the eqiad1 region so that you can start building out new servers there, please open a quota request here: https://phabricator.wikimedia.org/project/profile/2880/
The migration process for Toolforge will be utterly different -- in the meantime people who only use Toolforge can disregard all of this for the time being.
Neat Extensions
Published 21 Sep 2018
by /u/sleazedorg
on MediaWiki.
Bartosz Dziewoński, also known as Matma Rex, has been a developer with the Wikimedia Foundation since 2014, mostly working in the Editing team. He has been involved in projects including VisualEditor, OOjs and OOUI.
Nikhil Kumar and Yashdeep Thorat are the two students I mentored during the recently-concluded Google Summer of Code 2018. Nikhil (left) is a student at IIT Guwahati in Guwahati, Assam, India. He worked on a project to improve the interface and functionality of the Special:Drilldown page in the Cargo MediaWiki extension. Yashdeep (right) is a student at BITS Pilani in Hyderabad, Telangana, India. He worked on a project to add a new special page, Special:MultiPageEdit (which lets users edit multiple pages via a spreadsheet-like interface), to the Page Forms MediaWiki extension.
When Wikimedia Labs (the umbrella-project now known as 'Cloud VPS') first opened to the public in 2012 it was built around OpenStack Nova version 'Diablo'.[1] Nova included a simple network component ("nova-network") which works pretty well -- it assigns addresses to new VMs, creates network bridges so that they can talk to the outside internet, and manages dynamic firewalls that control which VMs can talk to each other and how.
Just as we were settling into nova-network (along with other early OpenStack adopters), the core developers were already moving on. A new project (originally named 'Quantum' but eventually renamed 'Neutron') would provide stand-alone APIs, independent from the Nova APIs, to construct all manners of software-defined networks. With every release Neutron became more elaborate and more reliable, and became the standard for networking in new OpenStack clouds.
For early adopters like us, there was a problem. The long-promised migration path for existing nova-network users never materialized, and nova-network got stuck in a kind of support limbo: in version after version it was announced that it would be deprecated in the next release, but nova-network users always pushed back to delay the deprecation until an upgrade path was ready. Finally, in late 2016 nova-network was finally dropped from support, but still with no well-agreed-on upgrade path.
So, after years of foot-dragging, we need to migrate (T167293) our network layer to Neutron. It's going to be painful!
The Plan
Since there is not an in-place upgrade path, Chase and Arturo have built a new, parallel nova region using Neutron that is named 'eqiad1-r'. It shares the same identity, image, and DNS service as the existing region, but instances in the eqiad1-r region live on different hosts and are in a different VLAN with different IPs. I (Andrew) will be pulling projects, one at a time, out of the existing 'eqiad' region and copying everything into 'eqiad1-r'. Each instance will be shut down in eqiad, copied to eqiad1-r, and started up again. The main disruption here is that once moved, the new VMs will have a new IP address and will probably be unable to communicate with VMs in the old region; for this reason, project migration will mean substantial, multi-hour downtime for the entire VPS project.
Here are a few things that will be disrupted by IP reassignment:
Internal instance DNS (e.g. <instance>.<project>.eqiad.wmflabs)
External floating-IP DNS (e.g. <website>.<project>.wmflabs.org)
Dynamic web proxies (e.g. http://<website>.wmflabs.org>)
Nova security group rules
Anything at all internal to a project that refers to another instance by IP address
I'm in the process of writing scripted transformations for almost all of the above. Ideally when a VM moves, the DNS and proxy entries will be updated automatically so that all user-facing services will resume as before the migration. The one thing I cannot fix is literal IP references within a project; if you have any of those, now would be a good time to replace those with DNS lookups, or at the very least, brace yourself for a lot of hurried clean-up.
Once we've run through a few trial migrations, I'll start scheduling upgrade windows and coordinating with project admins. We'll probably migrate Toolforge last -- there are even more issues involved with that move which I won't describe here.
This is another technical-debt/cleanup exercise that doesn't really get us anything new in the short-run. Moving to Neutron clears the path for an eventual adoption of IPv6, and Neutron has the potential to support new, isolated testing environments with custom network setups. Most importantly however, this will get us back on track with OpenStack upgrades so that we can keep getting upstream security fixes and new features. Expect to hear more about those upgrades once the dust settles from this migration.
The Timeline
Honestly, I don't know what the timeline is yet. There are several projects that are wholly managed by Cloud Services or WMF staff, and those projects will be used as the initial test subjects. Once we have an idea of how well this works and how long it takes, we'll start scheduling other projects for migration in batches. Keep an eye on the cloud-announce mailing list for related announcements.
How you can help
Fix any literal IP references within your project(s). Replace them with DNS lookups. If they can't be replaced with lookups, make a list of everywhere that they appear and get ready to edit all those places come migration day
Delete VMs that you aren't using. Release floating IPs that you aren't using. Delete Proxies that aren't doing anything. The fewer things there are to migrate, the easier this will be.
[1] OpenStack releases are alphabetical, two per year. The current development version is Rocky (released late 2018); WMCS is currently running version Mitaka (released early 2016) and Neutron was first released as part of version Folsom (late 2012). So this has been a long time coming.
Dustin Phillips is a co-executive director of ICANNWiki, the semi-official wiki of ICANN, the organization that maintains the internet's Domain Name System. He has been with ICANNWiki since 2015. He is also the Assistant Director of the Washington, D.C. Chapter of the Internet Society, and has helped introduce MediaWiki to that organization as well.
Highlights from episodes 6-11! It's another BTB Digest. Hear Daren Welsh and James Montalvo on not starting a wiki from scratch, Dan Barrett on appointing "page curators", Kunal Mehta on the importance of Requests for Comment, Ben Fletcher on the "lightbulb moment" of Semantic MediaWiki, Markus Krötzsch on the very random origins of Semantic MediaWiki, and more!
Remco de Boer is a partner at ArchiXL, a MediaWiki-based enterprise architecture consulting company in the Netherlands. He is also the CTO of ArchiXL's subsidiary, XL&Knowledge, which also does MediaWiki-related consulting. He has been working at ArchiXL, and with MediaWiki, since 2009.
Stanislav "Stas" Malyshev is a developer who is currently part of the Wikimedia Search Platform team, working on search within both MediaWiki and Wikidata. He has worked for the Wikimedia Foundation since 2014. He previously worked on PHP as part of Zend Technologies, and remains involved with the development of PHP. He also worked at SugarCRM.
We’ve replaced Tidy, a tool that fixes HTML errors, with a HTML5-based tool. Given a HTML5 library, replacing Tidy is pretty straightforward, but it took us three years to finally flip the switch. In this blog post, we’ll explore how the time was spent which also throws light on the complexities of making changes to certain pieces of the technical infrastructure powering Wikimedia wikis.
This switch was a collaborative effort between the Parsing, Platform, Community Liaison teams and other individuals (from the Product side) at the Wikimedia Foundation and volunteer editing communities on various wikis. Everyone involved played important and specific roles in getting us to this important milestone. In this post, the authors use “we” as a narrative convenience to refer to some subgroup of people above.
First: Some background
What is Tidy?
Tidy is a library that fixes HTML markup errors, among other things. It was developed in the 1990s when HTML4 was the standard and different browsers did not deal with ill-formed HTML markup identically leading to cross-browser rendering differences.
Badly formed markup is common on wiki pages when editors use HTML tags in templates and on the page itself. (Example: unclosed HTML tags, such as a <small> without a </small>, are common). In some cases, MediaWiki itself introduces HTML errors. In order to deal with this, Tidy was introduced into MediaWiki around 2004 to ensure the output of MediaWiki was well-formed HTML and to ensure it renders identically across different browsers.
Tidy played a very important role in MediaWiki’s early development by reducing the complexity of the core wikitext parser since the parser didn’t have to worry about generating clean markup and could instead focus on performance. It also freed us from having to write and maintain a custom solution which was important given that most MediaWiki development then relied on volunteers.
Why did we replace it?
The technological landscape of today is very different from 2004, the early days of MediaWiki. First, HTML5 is the standard today, and the parsing algorithm for HTML5 is clearly specified, which has led to compatible implementations across browsers and other libraries. This algorithm also clearly specifies how broken markup should be fixed.
HTML4 Tidy was no longer maintained for a number of years. It was based on HTML4, so it drifted away from the latest HTML5 recommendations. Additionally, it creates changes that are unrelated to fixing markup errors. For example, it removes empty elements and adds whitespace between HTML tags, which can sometimes change rendering.
We want to control the maintenance of this tool so that we choose when and how to upgrade it. This is important because we want to control changes to wikitext behavior and be prepared for that change.
In MediaWiki’s support for visual editing, when edited HTML is converted back to wikitext, spurious changes to wikitext have to be avoided. To support this, Parsoid (an alternate wikitext parser slated to be the default over the next couple years) uses a standard HTML5 parsing library and relies on being able to precisely track and map generated HTML to input wikitext. Tidy-html5, with the additional changes it makes to the HTML, complicates this and wouldn’t be a suitable HTML5 library for Parsoid.
As MediaWiki itself evolves, we want to use DOM-based strategies for parsing wikitext compared to the current string-based parsing. Tidy does not provide us a DOM currently.
Lastly, we want to retain the flexibility of being able to replace one HTML5 library with another without impacting correctness and functionality. Custom HTML changes can lock us in without easy replacement options (as this current project demonstrates).
So, while Tidy has served us well all these years, it was time to upgrade to a different solution that is more compatible with the technological path for MediaWiki.
What did we replace it with?
After a bunch of experimentation, we eventually replaced Tidy with RemexHtml, which is a PHP implementation of the HTML5 tree-building algorithm. This was developed and is being maintained by the Parsing and Platform teams at the Wikimedia Foundation. RemexHtml draws on (a) the domino node.js library that is used by Parsoid and (b) earlier work developing Tidy-compatibility passes in Html5Depurate which was the original Tidy replacement solution.
Since Tidy has been enabled on Wikimedia wikis since 2004, wiki markup on all these wikis have come to subtly depend on some Tidy functionality. In order to ease the transition out of Tidy, MediaWiki implements some Tidy-compatibility code on top of RemexHtml. For example, while RemexHtml does not strip empty elements, MediaWiki tags them with a CSS class so wikis can choose to hide them to mimic Tidy’s stripping.
What made this replacement difficult?
There were a bunch of issues that made this project fairly difficult:
We needed to identify a suitable HTML5 library to replace Tidy.
We had to build the testing infrastructure to accurately assess how this change would affect page rendering on wikimedia wikis.
We had to then address the impact of any changes we identified during testing.
Identifying a suitable replacement library
Firstly, there were no suitable implementations of the HTML5 tree building algorithm in PHP. The only real candidate was html5-php, but it doesn’t implement some key parts of the spec. So, we initially narrowly focused this on what would work for wikis on the Wikimedia cluster versus what would make sense for MediaWiki as a software package. By late 2015, we had Html5Depurate, which was a wrapper on top of validator.nu, a Java HTML5 library. T89331 documents this discussion for those interested in the details.
To run ahead of the narrative a bit, but to bring this topic to completion, in the 2016–2017 timeframe, two independent and somewhat orthogonal efforts on the Parsing team coalesced into RemexHtml, a PHP implementation of the HTML5 parsing algorithm. We adopted this as the Tidy replacement solution since it had good performance and wider applicability beyond Wikimedia.
Testing infrastructure to identify impacts on page rendering
Since wikis have come to depend on Tidy, if we were to replace Tidy with a HTML5 tool, we expected rendering on some pages would change in some way. To assess this impact, we set up a mass visual diffing infrastructure with two MediaWiki instances (running in Cloud Services): one using Tidy and another using Tidy’s replacement. These instances ran a multi-wiki setup with 60k+ pages from 40 wikis. On a third server, we fetched pages from both these VMs, used PhantomJS to snapshot these pages, and used UprightDiff to identify differences in rendering and assign that difference an actionable numeric score.
By end of May 2016, after some rounds of fixes and tests, we found multiple categories of rendering differences, and while 93% of pages were unaffected in our test subset, the 7% of pages affected was more than what we had anticipated. So, it was clear to us that wiki pages had to be fixed before we could actually make the switch. So, this now brought to the fore the third issue above: how do we actually make this happen?
What tools and support did we provide editors / wikis?
We were left with three problems to address:
Identify which pages need fixing
What needed fixing in those pages
How fixes could be verified
In practice, our work didn’t follow this clean narrative order, but nevertheless, we ended up providing editors two tools, ParserMigration and Linter, which addressed these problems.
ParserMigration
In order to let editors figure out how any particular page would be affected by the change, around July 2016 we developed the ParserMigration extension, which lets editors preview pages side-by-side with Tidy and with Tidy’s replacement (originally Html5Depurate, now RemexHtml). This lets them edit the page and verify that the edit eliminates any rendering differences by showing them updated previews.
Linter
Parsoid has the ability to analyze HTML and identify problematic output and then map it back to the wikitext that produced it. Based on this, a GSoC student had prototyped a linting tool in 2014, and in October 2016 we decided to develop that prototype into a production-ready solution for the Tidy replacement project. Through late 2016 and early 2017, we built the Linter extension to hook into MediaWiki, receive linter information from Parsoid, and display wikitext issues to editors on their wikis via the wiki’s Special:LintErrors page.
We analyzed the earlier visual diff test results and added linter categories in Parsoid to identify wikitext markup patterns that could cause those rendering differences. We started off with three linter categories in July 2017 and eventually ended up with nine high-priority linter categories by January 2018 based on additional testing and feedback from early deployment on some wikis.
Ongoing community engagement and phased deployment
In parallel with developing tooling, from late 2016 through mid-2017 we worked on a plan to engage editors on various wikis to fix pages and templates in preparation for Tidy replacement. We prepared a FAQ, started writing Linter help pages, developed a deployment plan and timeline, polished and deployed RemexHtml, Linter, ParserMigration, drafted a public announcement about this upcoming change and sent it out on a couple of mailing lists on July 6, 2017 and Tech News. We provided wikis a one-year window to start making changes to their wikis to prepare for the change.
We identified Italian and German Wikipedias as two large early adopter wikis and with their consent, switched them over on December 5th 2017. This early deployment gave us very good feedback—both positive and negative. German deployment went flawlessly and Italian deployment exposed some gaps and let us identify additional Linter categories for flagging pages that needed fixing. Deployment to Russian Wikipedia in January 2018 forced us to change wikitext semantics around whitespace to reproduce Tidy behavior.
Editors and volunteers for their part developed helppages and additional tools to help fix pages. Starting April 2018, for English Wikipedia, we helpedindividualwikiprojects with lists of pages that need fixing, and we contacted wikis with the highestnumbers of errors and helped connect them to volunteers and information about how to resolve the errors in advance. One of us even fixed 100s of templates on 10s of wikis (primarily small wikis) to nudge them along.
All along, we continued to gather weekly stats on how wikis were progressing with fixing pages, and also ran weekly visual diff tests on live wiki content to collect quantitative data about how this reduced rendering changes on pages. We continued to post occasional updates on the wikitech-ambassadors list and Tech News to keep everyone informed about progress.
Summary
This ongoing community engagement, communication, testing, monitoring, and phased deployment effort was crucial in letting us meet our one-year deployment window for wikis to switch over with a minimum of disruption to readers. Equally importantly, an active embrace by various wikis of this effort has let the Foundation make this much-needed and important upgrade of a key piece of our platform.
What next? What does this enable?
Since the preferred implementation of TemplateStyles has a dependency on RemexHtml, unblocking its deployment is the most immediate benefit to editors of the switch to RemexHtml. Some bug fixes in MediaWiki have benefited from RemexHtml’s real HTML5 parsing, and we hope that editors will find the use of standard HTML5 parsing rules a boon when chasing down rendering issues with their own wikitext. Going forward, there are two parallel efforts that benefit from RemexHtml: balanced templates, which could make output more predictable and faster for readers and editors, and a planned port of Parsoid from Node.js to PHP and the final replacement of the legacy Parser. Eventually, as we start thinking of ways to evolve wikitext for better tooling, performance, reasoning ability, and fewer errors, DOM-based solutions will be very important.
But all that is in the future. For now, we are happy to have successfully reached this milestone!
Subbu Sastry, Principal Software Engineer Tim Starling, Lead Platform Architect Wikimedia Foundation
Between 2017-11-20 and 2017-12-01, the Wikimedia Foundation ran a direct response user survey of registered Toolforge users. 141 email recipients participated in the survey which represents 11% of those who were contacted.
Demographic questions
Based on responses to demographic questions, the average [1] respondent:
Has used Toolforge for 1-3 years
Developed 1-3 tools & actively maintains 1-2 tools
Spends an hour or less a week maintaining their tools
Programs using Python and/or PHP
Does 80% or more of their development work locally
Uses source control
Was not a developer or maintainer on Toolserver
[1]: "Average" here means a range of responses covering 50% or more of responses to the question. This summarization is coarse, but useful as a broad generalization. Detailed demographic response data is available on wiki.
Qualitative questions
90% agree that services have high reliability (up time). Up from 87% last year.
78% agree that it is easy to write code and have it running on Toolforge. Up from 71% last year.
59% agree that they feel they are supported by the Toolforge team when they contact them via cloud mailing list, #wikimedia-cloud IRC channel, or Phabricator. This is down dramatically from 71% last year, but interestingly this question was left unanswered by 36% of respondents.
59% agree that they receive useful information via cloud-announce / cloud mailing lists. Up from 46% last year.
52% agree that documentation is easy to find. This is up from 46% last year and the first time crossing the 50% point. We still have a long way to go here though!
96% find the support they receive when using Toolforge as good or better than the support they received when using Toolserver. Up from 89% last year.
50% agree that Toolforge documentation is comprehensive. No change from last year.
53% agree that Toolforge documentation is clear. Up from 48% last year.
Free form responses
The survey included several free form response sections. Survey participants were told that we would only publicly share their responses or survey results in aggregate or anonymized form. The free form responses include comments broadly falling into these categories:
Documentation (58 comments)
Platform (48 comments)
Workflow (48 comments)
Community (17 comments)
Support (6 comments)
Documentation
Comments on documentation included both positive recognition of work that has been done to improve our docs and areas that are still in need of additional work. Areas with multiple mentions include need for increased discoverability of current information, better getting started information, and more in depth coverage of topics such as wiki replica usage, Kubernetes, and job grid usage.
Comments about the Toolforge platform have been subcategorized as follows:
Software (26 comments)
The majority of software comments were related to a desire for newer language runtime versions (PHP, Java, nodejs, Python) and more flexibility in the Kubernetes environment.
Database (10 comments)
Database comments include praise for the new Wiki Replica servers and multiple requests for a return of user managed tables colocated with the replica databases.
Reliability (10 comments)
Reliability comments included praise for good uptime, complaints of poor uptime, and requests to improve limits on shared bastion systems.
Hardware (2 comments)
(sample too small to summarize)
Workflow
Deploy (12 comments)
The major theme here was automation for software deployment including requests for full continuous delivery pipelines.
Debugging (10 comments)
People asked for better debugging tools and a way to create a more full featured local development environment.
Monitoring (10 comments)
Monitoring comments included a desire for alerting based on tracked metrics and tracking of (more) metrics for each tool.
Improved workflows for remote editing and file transfer are desired.
Community
Comments classified as community related broadly called for more collaboration between tool maintainers and better adherence to practices that make accessing source code and reporting bugs easier.
Support
Support related comments praised current efforts, but also pointed to confusion about where to ask questions (irc, email, phabricator).
Markus Krötzsch is the professor for Knowledge-Based Systems in the Computer Science department at the Technical University of Dresden, in Germany. In 2005 he co-created, with Denny Vrandečić, the Semantic MediaWiki extension, for which he served as the project lead for around the next seven years. He also founded, and is still the president of, the Open Semantic Data Association, a German non-profit which, among other things, provides funding support for the annual SMWCon. Markus also provided important early assistance with Wikidata, a site released in 2012.
Ben Fletcher is a systems architect at the Information Systems and Services (ISS) cluster for the UK Ministry of Defence (MoD). He helped to select MediaWiki for use at the MoD in 2016, and currently does MediaWiki-related work full-time.
Kunal Mehta (also known as "legoktm") is a developer at the Wikimedia Foundation in the MediaWiki Platform team. He has been involved in MediaWiki development since 2010.
Hello, Your local friendly /r/MediaWiki moderator here. I'm sure you ended up here with a question about MediaWiki. That's great. We're a pretty small community here on reddit, but we are part of a larger community of people that don't frequent this venue. Well, some do.
It's complicated.
So, I wanted to highlight that there are other venues that you can use if you find yourself without an answer here.
I'd also like to plug the MediaWiki Stakeholders' User Group. They're a group of MediaWiki users that meet monthly to discuss MediaWiki and share best practices.
Full disclosure, I work for the Wikimedia Foundation, but am writing this here in my capacity as a volunteer.
So please, keep these in mind on your MediaWiki adventure. Keep talking here too, these are just suggestions. I'm just a mod, not a cop.
The best of episodes 1-5! Well, not really the best, but the most relevant (and maybe interesting) parts of the first five episodes, condensed into a short(-ish) 30 minute digest.
Here’s everything we published from the design, development, and data process for the page previews feature
A few weeks ago, we deployed the page previews feature to English Wikipedia. This deployment marked the completion of one of the largest changes we’ve made to the desktop version of Wikipedia in years. Since then, we’ve received a number of questions about our process, motivations, and documentation. Given that much of our work is already online, we thought it’d be nice to share a bit more.
As tech lead Jon Robson wrote in his blog post, page previews took us a pretty long time to complete. This long timeline was in part due to technical complexity as well as to our best attempts at rigour in terms of instrumentation, testing, and having thorough conversations with our communities on what they wanted the feature to be like in the long term. Here’s a list of the documentation we’ve gathered along the way:
General
The main MediaWiki page for the project contains an overview of the project and functionality, links to research and requirements, an overview of the history of the feature, and deployment plans.
Product
Product requirements and detailed descriptions of workflows and functionality: Before we deployed to any wikis, we refactored our code. As this marked somewhat of a fresh start, we made sure to collect all requirements for the feature ahead of time. We incorporated feedback from our communities to include all requested updates.
Initial blog post on launching this as a beta feature: The story of page previews goes far back. The feature was initially presented to logged-in users as a beta feature, then called “hovercards,” back in 2014. Since then, it has changed in appearance and functionality significantly.
Design
How we designed page previews for Wikipedia and what could be done with them in the future: Even though page previews may seem simple at first glance, many complexities lie beneath the surface. This blog post goes into detail on why this is the case, which issues particular to Wikipedia we had to consider in terms of designing the feature, and how these considerations translated into the final design
Records of architectural decisions: Here, you can see why we build page previews the way we did, and track the architectural decisions we made along the way.
API Specification: In the beginning, previews were in plaintext. Our communities were rightly interested in presenting page previews in html to allow for rendering content true to its original form. This makes sense – we didn’t want strange bugs and missing formulas to detract from the benefits of page previews. However, we did not want to process all of this HTML within the Page Previews client. The less work the client has to do to display a preview, the better. Thus, we built a new API that could generate summaries for page previews as well as for other similar features in the future.
Code details: For the engineers among you, this page contains details on the code for page previews and instructions on how to set the feature up for other wikis.
“Beacons”: This blog post highlights the process of identifying and replicating one of the most confusing bugs we’ve come across so far. During our first round of A/B testing, we ran into a very strange bug within our instrumentation. We were seeing duplicate events logged for every link hover and it tooks us a lot of effort to get to the core of the issue — a bug in the Firefox browser. We worked with the Mozilla team to resolve this issue and were able to continue measuring the performance of the feature bug-free.
Page previews front-end tooling: This series of blog posts explains the different technical decisions and choices in technology and tooling for the front-end part of the extension. The posts provide reasoning, explanations, pros and cons, and our conclusions.
mustache.js replaced with JavaScript template literals in Extension:Popups: The Popups MediaWiki extension previously used HTML UI templates inflated by the mustache.js template system. This post provides the reasoning behind replacing Mustache with ES6 syntax without changing existing device support or readability.
Data
2017-18 A/B Tests: Page Previews are designed to reduce the cost of exploring a link, as well as to promote learning, by allowing readers to gain context on the article they are reading or to quickly check the definition of an unfamiliar event, idea, object, or term without navigating away from their original topic. To gauge the success of the feature, we wanted to test these assumptions by performing an A/B test on the English and German wikipedias. This page includes details of our methodology, the hypotheses we decided to test, and our results.
Hovercards Usability Research: In addition to quantitative testing, we also wanted to test qualitatively to gain insight into user opinions on page previews. We looked into opinion based questions as well as overall usability – Do people like the feature? Do they know how to turn it on/off? Do they find it annoying? How do they feel about the presence and size of images? Etc, etc.
2016 A/B Test Results: Our first A/B test, while providing us valuable insight into the feature was most valuable as a means of improving before a larger scale test. Here, we gauged the performance of the feature on Hungarian, Italian, and Russian Wikipedias. During the process of collecting and analysing our data we also ran into a number of bugs and issues within our instrumentation that allowed us to refine and improve, making sure all subsequent tests were issue-free.
Greek and Catalan usability test: Back in 2015, we performed the first investigation into the performance of the feature. We ran a survey on beta users on Greek and Catalan Wikipedias. A number of issues and bugs were reported and user satisfaction was recorded using a survey. Users had generally favorable feedback, with the majority of users finding hovercards useful, easy to use, and enjoyable to use.
Olga Vasileva, Product Manager, Reading Product
Wikimedia Foundation
🕑 1 hour 9 minutes Dan Barrett is a longtime developer and project manager who worked for fifteen years at Vistaprint, where he created, and oversaw the development and maintenance of, the MediaWiki installation. He has also written numerous technical books for O'Reilly, including the 2008 book MediaWiki: Wikipedia and Beyond. Links for some of the topics discussed:
Daren Welsh and James Montalvo are flight controllers and instructors at the Extravehicular Activity (EVA) group at the Johnson Space Center at NASA. They first set up MediaWiki for their group in 2011; since then, they have overseen the spread of MediaWiki throughout the flight operations directorate at Johnson Space Center. They have also done a significant amount of MediaWiki development, including, most recently, the creation of Meza, a Linux-based tool that allows for easy installation and maintenance of MediaWiki.
@Bstorm was hired as an Operations Engineer. She joined us just before the Foundation's annual all hands event and got a crash course in the names and faces of about 300 co-workers. Brooke has a lot of prior experience in both systems administration and software development, and is coming up to speed quickly with the Cloud Services environment. Her recent projects include improvements to the Toolforge CDNJS mirror and enhancements for the automation tools we use to update the Wiki Replicas indexes and views.
Our third new team member in January was @Chicocvenancio. A long time Wikimedian and Toolforge user, Chico is working as a Technical Support contractor. If you stop by the #wikimedia-cloud irc channel and ask for !help Chico is likely to be one of the folks who tries to help you out.
@srodlund also officially became part of the team as a technical writer. Sarah had been working with us on an ad hoc basis for months, but in January we came to an agreement for her to spend 50% of her paid Foundation time working on technical writing projects. Sarah has many years of experience as both a technical writer and as a writing instructor. We are excited to have her leading our efforts to create a community of technical writing contributors for the many Wikimedia projects.
The team was also busy working on the 'normal' projects which, when things go well, are seldom noticed. Wikitech, Horizon, and the Toolforge admin console have been moved to new physical servers thanks to @Andrew. You can read more about the details in Running red-queen-style. @aborrero has been working on making software security updates easier to manage. @chasemp is progressing on our OpenStack Neutron migration project. The public facing parts of Dumps have been moved to new servers thanks to a collaboration by @madhuvishy and @ArielGlenn.
In Toolforge news, long time volunteer @zhuyifei1999 was granted Toolforge administrator rights. YiFei has been providing great technical support advice to our community and code contributions for Toolforge and related services for many months. The adminship gives him greater abilities to troubleshoot and correct problems for Toolforge tool maintainers.
🕑 33 minutes Brian Wolff (username Bawolff) works in the Security team at the Wikimedia Foundation, and has been doing MediaWiki and MediaWiki extension development since 2009. Links for some of the topics discussed:
Wikipedia has lots of content, but some of it is unreadable on smartphones because of their small screens. For years our software has had hidden content incompatible with mobile displays. This approach always bugged us because we want user-generated content to be visible. At last, we found a way to address the issue: TemplateStyles, a technology for editors to format content for mobile presentation.
What was out there before TemplateStyles?
Brad Jorsch: Historically, there have been two ways to style content on a MediaWiki site such as Wikipedia: use inline CSS everywhere, or add it to site-global files like MediaWiki:Common.css. The first is problematic because it means you have to repeat those styles every time you want to use them on different pages or even within the same page. The first is also an issue because some features, like the ability to specify styles for different screen sizes, aren’t available to inline styles. The second is problematic because only wiki administrators can edit these site-global files, and the CSS could quickly grow to huge sizes if every special case were added there.
What problem does TemplateStyles solve?
Brad: What we wanted is a way for non-administrator contributors to be able to create reusable stylesheets that can be included in articles only as needed, with the ability to specify styles for different-sized devices. Since it makes most sense to use this in conjunction with MediaWiki’s existing wikitext templating, we called it TemplateStyles. It was one of those ideas that was hanging around for a while, waiting for someone to have the time to pick it up.
In early 2016, User:Coren picked up the idea as a volunteer project. Coren created an initial prototype of the software, but several security issues were identified that future development would need to resolve. Coren, unfortunately, didn’t have the time to take it further. The Wikimedia Foundation’s Reading Infrastructure team later picked it up to finish the project. During the first half of 2017 Brad Jorsch wrote a standards-based CSS parser and sanitizer library for PHP to resolve the security issues, and wrote a new version of the TemplateStyles extension with the cooperation of Gergő Tisza to use it.
Gergő Tisza: This was the biggest part of the work. Not only did it solve the problem of safe user-generated CSS for Wikimedia, it also solved it for everyone running a PHP website of any kind. I think it’s one-of-its-kind—there are some other CSS parsers written in PHP, but none meant to deal with untrusted input.
Who will use TemplateStyles?
Brad: The main audience is the editors of MediaWiki sites, more specifically those who create templates that need styling. It could also find good use for wikis’ main pages and portals.
Chris Koerner: As Brad mentioned folks who maintain meta templates—like those regarding page issues ({{Article for deletion}}, {{Hoax}}, etc.), navigation aids, and in-article data displays like climate data or ratings—could benefit from using TemplateStyles to improve the accessibility of their work on multiple devices. There’s a lot of possibility across wikis where templates are used.
What has been the response so far?
Chris: User:Nirmos, the Swedish Wikipedian who we’ve worked with, was impressed with the Performance team’s willingness to monitor performance as they worked. They have also filed tasks and been happy with the team (Brad and Gergő in particular) and their responsiveness. Nirmos has been implementing TemplateStyles on the Swedish Wikipedia, which from an adoption perspective is great!
How does TemplateStyles help readers and template writers?
Brad: Template writers and design-inclined individuals will be able to style templates more easily, and will be able to design templates that look good on both desktop and mobile devices. Additionally, copying some templates (like the English Wikipedia’s message box templates) to other wikis can become easier, since those doing the import won’t have to find the right pieces of MediaWiki:Common.css to manually copy.
Readers should benefit as template writers take advantage of the ability to make styles better adapt to different devices.
Gergő: I also want to point out that this will improve template maintainability. MediaWiki:*.css changes are hard to test because they are loaded as external stylesheets, are cached, and are not integrated with the normal page rendering process. TemplateStyle styles are included in the page, and rendered via the normal mechanism, making the standard editing toolchain (such as TemplateSandbox) work. Also, there is no easy way for the wikitext editor to support inline styles. CSS pages can have a dedicated editor which helps editors with syntax highlight, validation, typeahead etc.
Chris/Adam: Are you good at writing CSS that works on both laptops and smartphones? Would you like to help make Wikipedia articles easier to read on smartphones with TemplateStyles? Submit a task in Phabricator, the Wikimedia task tracking software, with a request to have TemplateStyles enabled.
Anything else you’d like to add?
Adam Baso: TemplateStyles helps to fix the layout problem of complex information on smartphones. But we still have a challenge with heavyweight HTML, which is taxing on mobile device hardware (processor, RAM, etc.). Even if the layout looks good, the HTML may be overkill. In the future we’d like to figure out how to use TemplateStyles to reduce the HTML markup actually sent to mobile devices or at least minimize the hardware impact on mobile devices. For devices with an even smaller footprint, like smart watches and embedded devices, technology that can automatically change the HTML to accommodate the constrained hardware and expected format will be essential.
———
Brad Jorsch, Senior Software Engineer, MediaWiki Platform Adam Baso, Director, Reading Engineering Chris Koerner, Community Liaison Gergő Tisza, Senior Software Engineer, Reading Infrastructure Wikimedia Foundation
Bernhard Krabina is a researcher and consultant for KDZ, the Centre for Public Administration Research, a Vienna, Austria-based nonprofit that focuses on improving and modernizing technology-based solutions in government at all levels within Europe. He has been involved with MediaWiki in government for the last 10 years.
I've spent the last few months building new web servers to support some of the basic WMCS web services: Wikitech, Horizon, and Toolsadmin. The new Wikitech service is already up and running; on Wednesday I hope to flip the last switch and move all public Horizon and Toolsadmin traffic to the new servers as well.
If everything goes as planned, users will barely notice this change at all.
This is a lot of what our team does -- running as fast as we can just to stay in place. Software doesn't last forever -- it takes a lot of effort just to hold things together. Here are some of the problems that this rebuild is solving:
T186288: Operating System obsolescence. Years ago, the Wikimedia Foundation Operations team resolved to move all of our infrastructure from Ubuntu to Debian Linux. Ubuntu Trusty will stop receiving security upgrades in about a year, so we have to stop using it by then. All three services (Wikitech, Horizon, Toolsadmin) were running on Ubuntu servers; Wikitech was the last of the Foundation's MediaWiki hosts to run on Ubuntu, so its upgrade should allow for all kinds of special cases to be ignored in the future.
T98813: Keeping up with PHP and HHVM. In addition to being the last wiki on Trusty, Wikitech was also the last wiki on PHP 5. Every other wiki is using HHVM and, with the death of the old Wikitech, we can finally stop supporting PHP 5 internally. Better yet, this plays a part in unblocking the entire MediaWiki ecosystem (T172165) as newer versions of MediaWiki standardize on HHVM or PHP 7.
T168559: Escaping failing hardware. The old Wikitech site was hosted on a machine named 'Silver'. Hardware wears out, and Silver is pretty old. The last few times I've rebooted it, it's required a bit of nudging to bring it back up. If it powered down today, it would probably come back, but it might not. As of today's switchover, that scenario won't result in weeks of Wikitech downtime.
T169099: Tracking OpenStack upgrades. OpenStack (the software project that includes Horizon and most of our virtual machine infrastructure) releases a new version every six months. Ubuntu packages up every version with all of its dependencies, and provides a clear upgrade path between versions. Debian, for the most part, does not. The new release of Horizon is no longer deployed through an upstream package at all, but instead is a pure Python deploy starting with the raw Horizon source and requirements list, rolled into Wheels and deployed into an isolated virtual environment. It's unclear exactly how we'll transition our other OpenStack components away from Ubuntu, but this Horizon deploy provides a potential model for deploying any OpenStack project, any version, on any OS. Having done this I'm much less worried about our reliance on often-fickle upstream packagers.
T187506: High availability. The old versions of these web services were hosted on single servers. Any maintenance or hardware downtime meant that the websites were gone for the duration. Now we have a pair of servers with a shared cache, behind a load-balancer. If either of the servers dies (or, more likely, we need to reboot one for kernel updates) the website will remain up and responsive.
Of course, having just moved wikitech to HHVM, the main Wikimedia cluster is being upgraded from HHVM to PHP 7, and Wikitech will soon follow suit. The websites look the same, but the race never ends.
Mike Cariaso is the co-founder of SNPedia, a MediaWiki-based repository of genomic information (founded in 2006), and the creator of Promethease, personal genetic analysis software that uses SNPedia's data.
To be honest, before becoming an Outreachy intern at the Wikimedia Foundation, I had never thought about many of the technical aspects of Wikimedia projects. Obviously the work isn’t completed with miracles and magic, but the full complexity and importance of all the work done behind the scenes did not occur to me until I got involved with one of the most important aspects of a free software project: documentation.
My role is dedicated to finding strategies to increase the number of people translating user guides. But before exploring possible ways to find new contributors, I needed to answer four questions:
What do we define as a user guide?
Is documentation well written?
Are we capable of welcoming new translators?
What is the current state of user guide translations?
While the answer for the first question might seem obvious for those extremely familiar with how wikis work, it was a source of confusion to me. As I searched for more information on subjects I was struggling with as a translator, I got lost very easily. I eventually ended up with multiple tabs of multiple wikis open, with little idea as to which one I ought to be relying on. But as I learned the conventions behind the organization of wikis, it became clear that what I was looking for was the pages under the Help namespace.
As for the state of documentation, the first thing I did when studying MediaWiki was to look for their style guide. There are several ways to convey a message, and that’s why style guides are an essential tool when writing documentation: they provide guidelines which enforce consistency, setting standards to be followed, and quality references to be seeked. They are the ultimate expression of how the project communicates with people, and are therefore an important part of the brand identity. Consequently, the absence or incompleteness of a project’s style guide will have direct influence on how the readers’ perspective of it.
MediaWiki’s style guide is far from perfect, especially as it relies too much on external references without highlighting which practices it considers the best. Unfortunately, this is a problem that is not confined solely to MediaWiki, as it shows up on other documentation like the Translation best practices. Writers end up without good and reliable resources to do their work, leading to difficulty in establishing a target audience and a proper style of writing. And users, especially new users, may face problems to understand new concepts and processes.
As a person new to the Wikimedia movement, I experienced first hand what is like to be an extremely confused and overwhelmed newcomer as I translated pages like CirrusSearch. It took me days to get used to the Translate extension workflow and weeks to understand the most basic concepts behind it. And as I learned more, I realized that my path to begin contributing with technical translations was extremely erratic and far from ideal.
The process to become a translator needs to be easy to follow and to understand. Tools and resources have to be presented briefly but effectively so newcomers are aware of where to find answers to their questions. I believe Meta:Babylon/Translations is the most recommended page to present to newcomers, but there should be also initiatives to improve it creating new or complementary forms of introduction and training as instructional videos. That way, we will welcome those who are new to the movement better.
Now, as much as I wish to make content available to all languages, it’s essential to focus our attention on those which are spoken by the most active communities. There is a substantial effort by Community Liaisons to provide support to those languages, including the creation of a list of active tech translators, so I used that as a reference to understand who we need to recruit.
Chinese, Catalan, Brazilian Portuguese, European Portuguese, French, and Polish are the languages with the highest translation rate on mediawiki.org. However, of these six languages, only two (Chinese and French) are featured in similar positions in the ranking by average views in a month, and only four (Chinese, French, Brazilian Portuguese and Polish) are among the ten most accessed languages. On the other hand, Swedish, Hungarian, Persian, Finnish, Turkish and Arabic are the languages with the lowest translation rates. Swedish and Turkish positions are similar in both rankings. However, surprisingly, the positions of the other languages in the completion ranking and the pageviews ranking differ from lot, especially the Help: Contents page in Arabic, which is the seventh language with the most accesses.
To understand the reasons behind those numbers is not just a matter of comparing number of pageviews and translation rates; it is necessary to consider social aspects such as the proficiency in English of the speakers of those languages. Consider the EF EPI index as a reference: countries like Netherlands, Sweden, Finland, Germany, Poland, Hungary, Czech Republic and Portugal have “very high” or “high” proficiency rates. Greece, Argentina, Spain. Hong Kong, South Korea, France and Italy have “moderate” proficiency levels. And China, Japan, Russia, Taiwan, countless Latin American countries like Brazil and Colombia, Iran, Afghanistan and Qatar are among those with “low” or “very low” proficiency. This helps to explain, for example, why there is such a high demand for documentation in Arabic even though the translation rate is one of the lowest.
Other important factors are the possibility of access to Wikimedia projects (which is more difficult in countries like Turkey), recognition level of Wikimedia projects in several countries (as evidenced by the Inspire campaigns) and the organization of the communities in question.
Still, while being as large as the Wikimedia Foundation and its projects comes with a set of downsides, it also comes with a good amount of advantages. Wikimedia projects are consolidated as a reference in open knowledge and are admired by thousands of people. Those who read and those who contribute believe in our values and quality of work, so the most sensible thing to do to improve the current state of translations in user guides is to ask for their help.
Translation teams usually have a small amount of people, and this works in our favor as it’s possible to make a lot of progress with few contributors. And while it’s viable to find technical translators among people who already contribute to other Wikimedia or free and open-source projects, it’s also beneficial to the Wikimedia movement and MediaWiki to look for new volunteers. After all, most of contributors already dedicate their free time to specific projects. Although I am sure some would love to find room to help (and they are welcome!), this can become overwhelming quickly.
So, to find new translators, we need to look for places where diversity is welcomed and open knowledge is valued. We also need people that speak their native language well and also understand English at, at least, an intermediate level. Because of that, reaching out to university students and professors is our best bet, given this kind of collaboration has been growing in the last few years.
Talking to professors, especially those who dedicate their studies to fields as linguistics and translation, can be a valuable source of knowledge and the beginning of a partnership with universities to help us develop, for instance, a fitting set of best translation practices for MediaWiki. This is, moreover, one of the subjects of a conversation I am having with a professor involved with the coordination of the Translation course of the Federal University of Uberlândia (UFU).
As for students, there are multiple reasons I suspect they would be wonderful contributors. While they are encouraged to learn English throughout their time in the university due to professional demands, there are little to no opportunities to make use of the knowledge they have gained outside their classrooms. In addition to that, they are stimulated to look for different but relevant extracurricular activities to perform, but most of them can’t be done from the comfort of their home.
Technical translations provide them a chance to put their fluency to a test while improving their vocabulary and reading comprehension. Translating documentation is also a great and easy way to begin contributing to Wikimedia projects, as the Translation extension offers translators an easy-paced workflow and you learn more about organizational nuances and technical details the more you translate.
Therefore, in recent months I have explored two fronts of work: communication with professors and others involved with university administration, publicizing the role of technical translator as an interesting extracurricular activity for students, and direct dialogue with said students, making use of promotionalmaterials making use of the relationship between Wikipedia and MediaWiki, and directing them to a shorter version of the Translate extension user documentation. The search for these two groups is done in three ways: direct but virtually through direct communication through emails or messages on social networks such as Twitter; in person, in meetings with coordinators of language schools or undergraduate courses; indirectly through the dissemination of promotional material made by volunteer students at various universities. The test of this strategy has been done locally in Brazil, my country of residence.
There are points of failure in the whole technical translation process—that goes from the quality of the source text to the lack of a strong translation community—and the path to finally solve them is long. MediaWiki needs to look up to good examples of documentation practices, like Atlassian or Write the Docs and establish and enforce a set of good practices for its documentation. It also needs to improve its localization practices, looking up to examples as Mozilla Firefox and improving resources made for technical translators. Providing a better training, making available tutorials more based on videos or other visual resources and less on text, is a better way to introduce newcomers to the tools they will use. Simple but effective introductions, like the one provided on Meta:Babylon, are also essential and need to be more publicized.
Lastly, building bridges between those who are already long-time contributors and those new to the movement is a must. While you can contact other translators through the translators mailing list, it is still a way of contact with a great amount of limitations. It isn’t a proper place to have real-time discussions and email is becoming a less used mean of communication. Promoting the establishment teams for each language, encouraging them to create and organize their own conventions for recurrent translations and writing style, and electing volunteers among them to communicate directly with newcomers will provide all of them a sense of belonging and support.
That said, the legacy of sixteen years of MediaWiki development, including all the user guides available at the moment, is still relevant, useful, and needs recognition as much as it needs attention. And that’s because when you dedicate a few hours of your month to translate documentation into your native language that covers important aspects of MediaWiki, you help us give users access to tools to enhance their contributions—and you provide them a better understanding of the interfaces they use. And while this helps to increase the quality of the content created, the chances of enhancing the software are also higher: more conscious users generate better reports on problems they faced, improving communication between them and developers.
Niklas Laxström is the creator and co-maintainer of translatewiki.net, the site where MediaWiki and most of its extensions (along with other software, like OpenStreetMap) gets translated into hundreds of languages. Niklas also works for the Wikimedia Foundation as part of the Language team, where he helps to develop code related to translation and internationalization, most notably the Translate extension.
Cindy Cicalese was a Principal Software Systems Engineer at MITRE for many years, where, among other things, she oversaw the creation and maintenance of over 70 MediaWiki installations, as well as development of many MediaWiki extensions. Last year she joined the Wikimedia Foundation as Product Manager for the MediaWiki Platform team.
I call this piece “Pig’s heart, with metadata”. Photo by Museum of Veterinary Anatomy FMVZ USP/Wagner Souza e Silva, CC BY-SA 4.0.
Wikimedia Commons is one of the world’s largest free-licensed media repositories with over 40 million image, audio, and video files. But the MediaWiki software platform that Commons is built on was designed for text, not rich media. This creates challenges for everyone who uses Wikimedia Commons: media contributors, volunteer curators, and those who use media hosted on Commons—on Wikimedia projects and beyond.
One of the main challenges for people who want to contribute media to Commons, or find things that are already there, is the lack of consistent metadata—information about a media file such as who created it, what it is, where it’s from, what it shows, and how it relates to the rest of the files in Commons’ massive archive.
The Structured Data on Commons (SDC) program aims to address this metadata problem by creating a more consistent, structured way of entering and retrieving the important metadata. This structured data functionality, based on the same technology that powers WikiData, will allow people to describe media files in greater detail, find relevant content more easily, and keep track of what happens to a piece of media after it’s uploaded.
One of the challenges SDC faces in this massive and ambitious redesign project is prioritization: What problems are we trying to solve? Who experiences those problems? Which ones should we tackle first? How can we avoid breaking other things in the process?
To answer these questions, we have been performing user research with different kinds of Commons participants, starting with GLAM projects—Galleries, Libraries, Archives, and Museums. We chose GLAM as the initial user research focus for a few reasons:
The people who upload media for GLAMs have different levels of previous experience with editing Wikimedia projects, ranging from complete newbies to veteran editors, and
The types of files being uploaded by GLAM projects, and the amount and kind of metadata available about those files, are similarly diverse
In other words, the motivations, needs, and workflows of GLAM project participants are diverse enough to potentially apply to many other kinds of people who contribute and consume media on Commons every day. Improving the Commons experience for GLAMs will likely benefit other users as well.
Our research into how to support GLAM projects during the transition to structured data on Commons began with a workshop in February 2017 at the European GLAM coordinators meeting. Between July and October 2017 we interviewed a dozen GLAM project participants from Africa, the Americas, Europe, and South Asia and ran surveys of GLAM participants and Commons editors.
We organized findings from the workshop, interviews, and surveys into five themes. Each theme represents a set of challenges and opportunities related to the way GLAM projects currently interact with Wikimedia Commons:
Preserving important metadata about media items
Functionality and usability of upload tools
Monitoring activity and impact after upload
Preparing media items for upload
Working with Wikimedia and Wikimedians
Through our research we were able to document a rich diversity of roles, goals, tools, and activities across GLAM projects, as well as identify motivations, unmet needs, and pain points that many GLAMs have in common. We also observed a number of inventive workarounds that GLAM project participants used to capture important metadata that wasn’t easy to record using the current systems like categories and templates. These workarounds illustrate the importance of metadata for making a file or a collection findable, useful, and usable, and the need for better ways to record all of that vital contextual information.
In the Structured Data on Commons program, we also regularly consult with Wikimedia Commons editors about how structured data will impact their work. With input from the Commons community, we developed a prioritized list of important community-developed tools for organizing media on Commons, which also helps us to understand typical workflows and to prioritize functionalities.
Research findings and community feedback will be combined into personas, journey maps, and user stories to help product teams set development priorities and define requirements for improving Commons file pages, upload tools, and search interfaces that use structured data.
A full report of our GLAM interview and survey research is available on the Research portal on meta.wikimedia.org, along with slides and a video of a recent presentation of findings.
The next steps of this project include additional interviews with Commons editors to understand how structured data will impact ongoing curation activities. We are also interested in speaking with re-users of Commons media outside of the Wikimedia movement to learn how structured data can make Commons an even more valuable global resource for high-quality free-licenced media—get in touch with us at jmorgan[at]wikimedia[dot]org and sfauconnier[at]wikimedia[dot]org.
Wikimedia has accepted six interns through the Outreachy program who will work on a wide variety of Wikimedia projects (five coding and one translation related) with help from twelve Wikimedia mentors from December 2017 through March 2018.
Outreachy is an internship program coordinated by Software Freedom Conservancy twice a year with a goal to bring people from backgrounds underrepresented in tech into open source projects. Seventeen open source organizations are participating in this round, and will be working with a total of 42 interns. (Six interns are participating from Wikimedia.) Accepted interns will be funded by the Wikimedia Foundation’s Technical collaboration team that coordinates Wikimedia’s participation in various Outreach programs.
There is a lot of technical documentation in English around Wikimedia projects and topics hosted on MediaWiki.org. This documentation is usually translatable but is rarely translated, at least in not more than a few languages. Also, becoming and staying engaged as a translator is difficult. This project will help develop outreach strategies to reach out to potential translators, with an ultimate goal of providing technical documentation to readers in the language they are comfortable.
Being able to take a sneak peek into your contributions can be rewarding in the open source world and keeps you motivated in staying involved. In Wikipedia, due to its highly collaborative nature, it’s not easy for the editors to take credit for the value they added to an article. This project would be a first step towards tackling this problem through a new tool that would allow Wikipedia editors to view a summary of their contributions.
Wikimedia Grants review and Wikimania scholarship web applications are two similar platforms that enable users to submit scholarship applications and for administrators to review and evaluate them. This project will help make planned improvements to these apps.
The MassMessage extension allows a user to send a message to a list of pages via special page Special:MassMessage. There are large wikis that use this extension already: Wikimedia Commons, MediaWiki, Meta-Wiki, Wikipedia, Wikidata, etc. This project is about refactoring the technical debt that has accumulated over years since this extension is in use to make it match recent MediaWiki standards.
Programs & Events Dashboard helps organize and track group editing projects on Wikipedia and other wikis (such as edit-a-thons). One of the major use cases of this dashboard is the Art+Feminism project, a worldwide program of edit-a-thons that take place in March every year. There was a range of problems identified during the 2017’s edition, and new features requested afterward. This project will focus on improving the Dashboard with help from organizers to better support the 2018’s edition.
Wikimedia’s current captchas can easily be cracked by spam bots, and it takes multiple attempts for a human to solve them. Moreover, the statistics show a failure rate of around 30%, and we don’t know what percentage of this is due to bots. Current captchas are problematic as they allow registration via bots, and trouble people with visual impairments and lacking English skills. This project aims to develop a revised Captcha system which would be friendlier to humans and harder for bots to crack.
You can stay up to date with the progress on these projects through the reports our interns will write on personal blogs. Our interns are quite excited about the opportunity and dedicated to making their project a successful one. One of the accepted interns wrote in their blog post before the results were out: “Even if my name doesn’t appear in the Outreachy’s interns page this Thursday I want to make a pin to celebrate what I made in the last two months. I dedicated a lot of time to contribute to Wikimedia and all the things I learned there were really important. I don’t regret anything..”
We would like to thank everyone who applied to Wikimedia. We received a total of fourteen robust proposals, out of which we chose six. Wikimedia mentors spent quite a lot of time mentoring candidates during the application period, in reviewing their pull requests, and giving them feedback on their proposals.
Stay tuned with Wikimedia’s participation in Outreach programs. If you are interested in applying for the next round of Outreachy, remember that the application will be due in the last week of March of 2018.
Srishti Sethi, Developer Advocate, Developer Relations Wikimedia Foundation
This post has been updated to add the name of one of the six Outreachy interns, and to correct name the mentors of the “Automatically detect spambot registration …” project.
Behind the hackathon: Six questions with events organizer Rachel Farrand
If you’ve attended a hackathon in the Wikimedia movement, you’ve likely encountered Rachel Farrand. Farrand, who has been working at the Wikimedia Foundation since 2011, helps ensure that technical events run smoothly—and that participants are well-versed in what to expect when they show up to code. We checked in with Rachel to learn more about the recently launched mentoring program, and to find out what her team learned in Montreal that will be applied to future events.
You’ve run a lot of hackathons. And yet, every time you run a new event, you change up some things. I’m wondering how you assess what to change, and where you focused your efforts during the Wikimania Hackathon?
Rachel Farrand: After every hackathon we collect feedback from participants and make changes to areas of our events that are not running as smoothly as the other areas. We also make changes based on our Wikimedia Foundation Technical Collaboration Team goals. For example right now we are trying to relate everything we do back to “onboarding and supporting new volunteer developers”. So our mentoring program and sessions for newcomers always get a lot of extra attention. (Related: What we learned by making both newcomers and experienced participants feel connected and engaged at the Vienna Hackathon.)
You mention that you changed the mentoring program this year. Can you talk a little bit more about how that program works?
Rachel Ferrand: Our mentoring program works to connect projects with a mentor and then with a newcomer or group of newcomers. Mentors are welcome to either come with their own project or be matched with one. One of the main changes for the Montreal hackathon was to pre-match mentors and projects with newcomers in advance of the hackathon so that they could begin to get to know each other and work in advance so they could start hacking right away when they arrived in Montreal. We spent the first morning giving newcomers an overview of Wikimedia tech and explaining their options so that choosing a project would be easier.
We also tried to simplify the mentoring program and incorporate it into the rest of the hackathon so that there would be more hacking time and so that newcomers could more easily meet other Wikimedia Developers who were not involved in the mentoring program. We did this by reducing the number of required meetings for both mentors and newcomers and moving the mentoring program from a separate room into a corner of the main hacking space.
Finally we gave a bit more structure to the mentor preparation by giving them time to create a “project poster” in advance of meeting with the newcomers and giving them an orientation as to how they could be effective and get help throughout the hackathon while the newcomers were getting the orientation to Wikimedia Tech.
What kinds of projects did people work on at this event?
Rachel Farrand: Here’s the list of the tasks from the event, and here’s the list of projects & notes about them from the showcase and the showcase video.
This year three volunteers from the Vienna Hackathon were sponsored to attend the Wikimania Hackathon and Wikimania. How did this come about? How do participants benefit from this kind of continuity?
Rachel Farrand: The Wikimedia technical community, just like the editing community, has volunteers at its core. We have noticed that attending events and making real connections with real people can inspire newcomers to stay around and become more involved. We choose three volunteers who attended the Vienna hackathon as “newcomers” to our technical spaces who did a lot of good work and could continue their work in Montreal, where they would meet an even larger and different part of our technical community. The people we choose were recommended by mentors, other community members, and Wikimedia Austria. We believe that the more positive personal connections a newcomer makes the more likely they will be to want to stay involved and we believe that in-person events really facilitate these connections. (Note: You can read an interview with two of the attendees.)
What changes are you thinking about for the next hackathon you put on?
Rachel Farrand:
We want to find more ways for people to help newcomers and for newcomers to feel comfortable and welcome. Some mentors want to commit to helping newcomers for the entire event but others may want to work on their own projects but spend only a few hours helping newcomers. Creating more pathways and options for helping will hopefully also work for newcomers with different needs.
We want to provide more documentation and support for mentors on how to be an effective mentor, how to prepare, how to communicate effectively, and when and how to get additional help for their newcomers.
We plan on having a much more extensive, clear, and diverse set of projects pre-matched with mentors and documented in advance of the hackathon. We also plan on having more small and easy tasks for newcomers to complete who are just learning about development.
We plan to continue to try and find new ways to engage our newcomers both in advance of the hackathons and after the hackathons are over. To provide support and community to them throughout the year. (Also see the Open Leaders Project)
Is there anything else you’d like to add?
Rachel Farrand: We have two more international hackathons coming up in 2018: One in Barcelona and on in Cape Town, South Africa. There are scholarship programs for both events, and anybody interested in getting involved in any area of Wikimedia tech is welcome to attend.
Interview by Melody Kramer, Senior Audience Development Manager, Communications Wikimedia Foundation
Ubuntu Trusty now deprecated for new WMCS instances
Long ago, the Wikimedia Operations team made the decision to phase out use of Ubuntu servers in favor of Debian. It's a long, slow process that is still ongoing, but in production Trusty is running on an ever-shrinking minority of our servers.
As Trusty becomes more of an odd duck in production, it grows harder to support in Cloud Services as well. Right now we have no planned timeline for phasing out Trusty instances (there are 238 of them!) but in anticipation of that phase-out we've now disabled creation of new Trusty VMs.
This is an extremely minor technical change (the base image is still there, just marked as 'private' in OpenStack Glance). Existing Trusty VMs are unaffected by this change, as are present ToolForge workflows.
Even though any new Trusty images represent additional technical debt, The WMCS team anticipates that there will still be occasional, niche requirements for Trusty (for example when testing behavior of those few remaining production Trusty instances, or to support software that's not yet packaged on Debian). These requests will be handled via phabricator requests and a bit of commandline magic.
A website has content— the articles; and it has a user interface — the menus around the articles and the various screens that let editors edit the articles and communicate with each other.
Wikipedia is massively multilingual, so both the content and the user interface must be translated.
The easiest way to translate Wikipedia articles is to use Content Translation, and that’s a topic for another post. This post is about getting all of the user interface translated to your language, as quickly and efficiently as possible.
The translation of the software behind Wikipedia is done on a website called translatewiki.net. The most important piece of software that powers Wikipedia and its sister projects is called MediaWiki. As of today, there are 3,865 messages to translate in MediaWiki, and the number grows frequently. “Messages” in the MediaWiki jargon are the text that is shown in the user interface, and that can be translated. Wikipedia also has dozens of MediaWiki extensions installed, some of them very important — extensions for displaying citations and mathematical formulas, uploading files, receiving notifications, mobile browsing, different editing environments, etc. There are around 4,700 messages to translate in the main extensions, and over 25,000 messages to translate if you want to have all the extensions translated. There are also the Wikipedia mobile apps and additional tools for making automated edits (bots) and monitoring vandalism, with several hundreds of messages each.
Translating all of it probably sounds like an enormous job, and yes, it takes time—but it’s doable.
Hebrew Wikipedia screenshot, text licensed under CC BY-SA 3.0.
In February 2011 or so — sorry, I don’t remember the exact date — I completed the translation into Hebrew of all of the messages that are needed for Wikipedia and projects related to it. All. The total, complete, no-excuses, premium Wikipedia experience, in Hebrew. I wasn’t the only one who did this, of course. There were plenty of other people who did this before I joined the effort, and plenty of others who helped along the way: Rotem Dan, Ofra Hod, Yaron Shahrabani, Rotem Liss, Or Shapiro, Shani Evenshtein, Inkbug (whose real name I don’t know), and many others. But back then in 2011 it was I who made a conscious effort to get to 100%. It took me quite a few weeks, but I made it.
The software that powers Wikipedia changes every single day. So the day after the translations statistics got to 100%, they went down to 99%, because new messages to translate were added. But there were just a few of them, and it took me a few minutes to translate them and get back to 100%.
I’ve been doing this almost every day since then, keeping Hebrew at 100%. Sometimes it slips because I am traveling or I am ill. It slipped for quite a few months because in late 2014 I became a father and didn’t have any time to dedicate to translation, and a lot of new messages happened to be added at the same time, but Hebrew is back at 100% now. And I keep doing this.
With the sincere hope that this will be useful for translating the software behind Wikipedia to your language, let me tell you how I do it.
Make sure you know your language code (a two or three letter standard abbreviation).
Go to your preferences, to the Editing tab, and add languages that you know to Assistant languages. For example, if you speak one of the native languages of South America like Aymara (ay) or Quechua (qu), then you probably also know Spanish (es) or Portuguese (pt), and if you speak one of the languages of the former Soviet Union like Tatar (tt) or Azerbaijani (az), then you probably also know Russian (ru). When available, translations to these languages will be shown in addition to English.
The translatewiki.net Translation Tool interface, CC BY 3.0.
Priorities
The translatewiki.net website hosts many projects to translate beyond stuff related to Wikipedia. It hosts such respectable Free Software projects as OpenStreetMap, Etherpad, MathJax, Blockly, and others. Also, not all the MediaWiki extensions are used on Wikimedia projects; there are plenty of extensions, with thousands of translatable messages, that are not used by Wikimedia, but only on other sites, but they use translatewiki.net as the platform for translation of their user interface.
It would be nice to translate all of it, but because I don’t have time for that, I have to prioritize. On my translatewiki.net user page I have a list of direct links to the translation interface of the projects that are the most important.
I usually don’t work on translating other projects unless all of the above projects are 100% translated to Hebrew. I occasionally make an exception for OpenStreetMap or Etherpad, but only if there’s little to translate there and the untranslated MediaWiki-related projects are not very important.
Start from MediaWiki most important messages. If your language is not at 100% in this list, it absolutely must be. This list is automatically created periodically by counting which 500 or so messages are actually shown most frequently to Wikipedia users. This list includes messages from MediaWiki core and a bunch of extensions, so when you’re done with it, you’ll see that the statistics for several groups improved by themselves.
Next, if the translation of MediaWiki core to your language is not yet at 13%, get it there. Why 13%? Because that’s the threshold for exporting your language to the source code. This is essential for making it possible to use your language in your Wikipedia (or Incubator). It will be quite easy to find short and simple messages to translate (of course, you still have to do it carefully and correctly).
Getting things done, one by one
Once you have the most important MediaWiki messages 100% and at least 13% of MediaWiki core is translated to your language, where do you go next?
I have surprising advice.
You need to get everything to 100% eventually. There are several ways to get there. Your mileage may vary, but I’m going to suggest the way that worked for me: Complete the easiest piece that will get your language closer to 100%! For me this is an easy way to strike an item off my list and feel that I accomplished something.
But still, there are so many items at which you could start looking! So here’s my selection of components that are more user-visible and less technical, sorted not by importance, but by the number of messages to translate:
Cite: the extension that displays footnotes on Wikipedia
Babel: the extension that displays boxes on userpages with information about the languages that the user knows
Math: the extension that displays math formulas in articles
Thanks: the extension for sending “thank you” messages to other editors
Universal Language Selector: the extension that lets people select the language they need from a long list of languages (disclaimer: I am one of its developers)
uls: an internal component of Universal Language Selector that has to be translated separately for technical reasons
Wikibase Client: the part of Wikidatathat appears on Wikipedia, mostly for handling interlanguage links
VisualEditor: the extension that allows Wikipedia articles to be edited in a WYSIWYG style
ProofreadPage: the extension that makes it easy to digitize PDF and DjVu files on Wikisource
I put MediaWiki core last intentionally. It’s a very large message group, with over 3000 messages. It’s hard to get it completed quickly, and to be honest, some of its features are not seen very frequently by users who aren’t site administrators or very advanced editors. By all means, do complete it, try to do it as early as possible, and get your friends to help you, but it’s OK if it takes some time.
Getting all things done
OK, so if you translate all the items above, you’ll make Wikipedia in your language mostly usable for most readers and editors.
But let’s go further.
Let’s go further not just for the sake of seeing pure 100% in the statistics everywhere. There’s more.
As I wrote above, the software changes every single day. So do the translatable messages. You need to get your language to 100% not just once; you need to keep doing it continuously.
Once you make the effort of getting to 100%, it will be much easier to keep it there. This means translating some things that are used rarely (but used nevertheless; otherwise they’d be removed). This means investing a few more days or weeks into translating-translating-translating.
Here’s the trick: Don’t congratulate yourself only upon the big accomplishment of getting everything to 100%, but also upon each accomplishment along the way.
One strategy to accomplish this is translating extension by extension. This means, going to your translatewiki.net language statistics: here’s an example with Albanian, but choose your own language. Click “expand” on MediaWiki, then again “expand” on “MediaWiki Extensions”, then on “Extensions used by Wikimedia” and finally, on “Extensions used by Wikimedia — Main”. Similarly to what I described above, find the smaller extensions first and translate them. Once you’re done with all the Main extensions, do all the extensions used by Wikimedia. (Going to all extensions, beyond Extensions used by Wikimedia, helps users of these extensions, but doesn’t help Wikipedia very much.) This strategy can work well if you have several people translating to your language, because it’s easy to divide work by topic.
Another strategy is quiet and friendly competition with other languages. Open the statistics for Extensions Used by Wikimedia — Main and sort the table by the “Completion” column. Find your language. Now translate as many messages as needed to pass the language above you in the list. Then translate as many messages as needed to pass the next language above you in the list. Repeat until you get to 100%.
For example, here’s an excerpt from the statistics:
Let’s say that you are translating to Malay. You only need to translate eight messages to go up a notch (901–894 + 1). Then six messages more to go up another notch (894–888). And so on.
Once you’re done, you will have translated over 3,400 messages, but it’s much easier to do it in small steps.
Once you get to 100% in the main extensions, do the same with all the Extensions Used by Wikimedia. It’s over 10,000 messages, but the same strategies work.
Good stuff to do along the way
Never assume that the English message is perfect. Never. Do what you can to improve the English messages.
Developers are people just like you are. They may know their code very well, but they may not be the most brilliant writers. And though some messages are written by professional user experience designers, many are written by the developers themselves. Developers are developers; they are not necessarily very good writers or designers, and the messages that they write in English may not be perfect. Keep in mind that many, many MediaWiki developers are not native English speakers. Report problems with the English messages to the translatewiki Support page. (Use the opportunity to help other translators who are asking questions there, if you can.)
Another good thing is to do your best to try running the software that you are translating. If there are thousands of messages that are not translated to your language, then chances are that it’s already deployed in Wikipedia and you can try it. Actually trying to use it will help you translate it better.
Whenever relevant, fix the documentation displayed near the translation area. Strange as it may sound, it is possible that you understand the message better than the developer who wrote it!
Before translating a component, review the messages that were already translated. To do this, click the “All” tab at the top of the translation area. It’s useful for learning the current terminology, and you can also improve them and make them more consistent.
After you gain some experience, create a localization guide in your language. There are very few of them at the moment, and there should be more. Here’s the localization guide for French, for example. Create your own with the title “Localisation guidelines/xyz” where “xyz” is your language code.
This post originally appeared on Amir’s personal Medium blog; a longer version of it is available on Aharoni in Unicode, ya mama. The opinions expressed in these posts are those of the author alone and may not be reflected by the Wikimedia Foundation or the Wikimedia community.
I first encountered the term “code health” in Max Kanat-Alexander’s post on the Google Testing Blog. It is simply defined as: “…how software was written that could influence the readability, maintainability, stability, or simplicity of code“.
The basic premise behind code health is that a developer’s quality of work, productivity, and overall happiness can be drastically improved if the code they work with is healthy.
That’s a pretty broad definition to say the least, but what’s equally important to the what code health is is the how it is then managed by a team. In Max’s post, he outlines how Google formed a small team called the Code Health Group. Each member of the team was expected to contribute an impactful percentage of their normal work efforts towards the Code Health Group’s priorities.
At the Wikimedia Foundation, we have formed a similar group. The Wikimedia Code Health Group (CHG) was launched in August 2017 with a vision of improving code health through deliberate action and support.
The CHG is made up of a steering committee, which plans to focus our improvement efforts towards common goals, and sub-project teams. The group will not only come up with prospective improvement initiatives, but be a conduit for others to propose improvements. The steering committee will then figure out staffing and needed resources, based on interest and availability of staff members.
In this post, I’ll talk a little bit about my definition of code health, and what we can do to manage it. Before that, however, I want to share why I became interested in working on this subject at the Foundation.
My deep dive into MediaWiki software
I’m a relatively new member of the Wikimedia Foundation—I joined the the Release Engineering team in January of 2017 with the goal of helping the Foundation and broader technical community improve its software development practices.
One of my first tasks was to understand our development practices and ecosystem, and I started by talking with developers who deeply understood MediaWiki — both in terms of what we did well and where there was room for improvement. My goal was to better understand the historical context for how MediaWiki was developed, and learn more about areas that we could improve. The result of these discussions are what I refer to as the “Quality Big Picture.” (I know, catchy name.)
What I learned during this discovery process was that there was room for improvement as well as a community of developers eager to improve the software.
Several weeks later, I had the opportunity to attend the Vienna Hackathon, where I hosted a session called “Building Better Software.” There, I shared what I had learned, and the room discussed areas of concern, including the quality of MediaWiki extensions and 3rd party deployments.
Other topics came up: I heard from long-time developers that some previous efforts to improve MediaWiki software lacked sustained support and guidance, and that efforts were ad-hoc and often completed by volunteers in their spare time.
The challenge was therefore two-fold: how to define and prioritize what to improve, and how to actually devote resources to make those improvements happen. It was these two questions that led me to Max’s blog post, and the subject of code health.
Let’s define “code health”
With some of the background laid out, I’d like to spend a little time digging into what “code health” means.
At a basic level, code health is about how easily software can be modified to correct faults, improve performance, or add new capabilities. This is broadly referred to as “maintainability”. What makes software maintainable? What are the attributes of maintainable software? This leads to another question: What enables developers to confidently and efficiently change code? Enabling developers after all, is what we are really targeting with code health.
Both a developer’s confidence and efficiency can vary depending on their experience with the codebase. But that also depends on the code health of the codebase. The lower the code’s health, then the more experience it takes for a developer to code with both confidence and efficiency. Trying to parse a codebase with low-code health is difficult enough for veteran developers, but it’s almost impossible for new/less experienced developers.
Interestingly, the more experienced a developer is with a code base, the more they want to see code health increase because code with lower health is more difficult and time-consuming to parse. In other words, high code health is good for both experienced and inexperienced developers alike.
Attributes
So what are the attributes of code health? For me, it boils down to four factors: simplicity, readability, testability, and buildability.
Simplicity
Let’s start with simplicity. Despite being subjective by nature, simplicity is the one attribute of code health that may be the most responsible for low code health. Fundamentally, simplicity is all about make code easier to understand. This goes against the common sentiment that because software is often written to solve complex problems, the code must be complex as well. However, that’s not always true: hard problems can be solved with code that’s easy to parse and understand.
Code Simplicity encompasses a number of factors. The size and signatures of functions, the use of certain constructs such as switch/case, and broader design patterns can all impact how easy a codebase is to understand and modify.
Despite its subjective nature, there are ways to measure code complexity such as the Cyclomatic and Halstead complexity measures. The former is already available against some of MediaWiki’s repos. But these tools come with a caveat because complexity measures can be misleading.
Readability
Another factor that affects code health is readability. Readability becomes more important as a development community grows in size. You can think of readability as the grammatical rules, sentence structures, and vocabulary that are present in any written human language.
Although a programming language’s syntax enforces a certain core set of rules, those rules are generally in place to provide a basic structure for a human to communicate with the computer, not another human. The paragraphs below are an example of how something can become significantly more complex without a common well understood set of rules. Given some time, you can still make sense of the paragraphs, but it is more difficult and error prone.
Much of what we see in-terms of poor readability is rooted in the not-so-distant history of programming. With limited computing resources such as processing, memory, and communication, programmers were encouraged to optimize code for the computer — not another human reader. But optimization is not nearly as important as it once was (There are always exceptions to that rule, however, so don’t set that in stone.). Today, developers can optimize their code to be human friendly with very little negative impact.
Examples of readability efforts include creating coding standards and writing descriptive function and variable names. It’s quite easy to get entangled in endless debate about the merit of one approach over another — for example, whether to use tabs or spaces. However, It’s more important to have a standard in place — whether it’s tabs or spaces — than to quibble about whether having a standard is useful. (It is.)
Although not all aspects of readability are easily measured, there is a fair amount of automated tooling that can assist in enforcing these standards. Where there are gaps, developers can encourage readability through regularly-scheduled code reviews.
Testability
Testability is often missing from many discussions regarding code health. I suspect that’s because the concept is often implied within other attributes. However, in my experience, if software is not developed with testability in mind, it generally results in software that is more difficult to test. This is not unlike other software attributes such as performance or scalability. Without some forethought, you’ll be rolling the dice in terms of your software’s testability.
I’ve found that it’s not uncommon for a developer to say that something is very difficult to test. Though this may sound like an excuse or laziness, it’s often pretty accurate. The question becomes: Could the software have been designed and/or developed differently to make it easier to test? Asking this question is the first step to make software testable.
Why should a developer change anything to make it easier to test? Remember the developer confidence I mentioned earlier? A big part of developer confidence when modifying code is based on whether or not they broke the product. Being able to easily test the code, preferably in an automated way, goes a long way to building confidence.
Buildability
The three attributes I’ve already mentioned are fairly well understood and are frequently mentioned when discussing healthy code. But there is a fourth attribute that I’d like to discuss. Code health is incomplete without including a discussion around Buildability, which I define as the infrastructure and ecosystem that the developer depends on to build and receive timely feedback on code changes they are submitting.
To be fair, you’d be hard pressed to find any material on code health that doesn’t mention continuous integration or delivery, but I think it’s important to elevate its importance in these discussions. After all, not being able to reliably build something and receive timely feedback hampers developer productivity, code quality, and overall community happiness.
The How
Now that we’ve talked about what code health is, we can discuss our next question: How do we address it? This is where we transition from talking about code to talking about people.
MediaWiki, like many successful software products/services, started with humble beginnings. Both its code base and developer base have grown as the Wikimedia projects have matured, and the personality of the code has evolved and changed as the code base expanded. All too often, however, this code is not refactored and “cruft”—or unwanted code—develops.
None of this of course is news to those of us at the Foundation and in the volunteer developer community that work on MediaWiki. There are many stories of individual or groups of developers going above and beyond to fix things and improve code health. However, these heroics are both difficult to sustain without formal support and resources, and often are limited in scope.
While speaking to developers during my first few months at the Foundation, I was inspired by what I heard, and I want to ensure that we’re working towards making these kinds of efforts to make our codebase more sustainable and even more impactful. Luckily, enabling developers is core to the mission of the Release Engineering team.
Simply forming the CHG isn’t sufficient. We also need to build momentum through ongoing action and feedback loops that ensure that we’re successful over the long-term. As a result, we’ve decided to take on the following engagement approach:
The Code Health Group is now meeting on a regular cadence.
The goal of these monthly meetings is to discuss ongoing code health challenges, prioritize them, and spin up sub-project teams to work towards addressing them.
Although the CHG has been formed and is meeting regularly, it’s far from complete. There will be plenty of opportunities for you to get involved over the coming months.
We’ll share what we learn.
The CHG will look to provide regular knowledge sharing through a series of upcoming blog posts, tech talks, and conferences.
We anticipate that the knowledge shared will come from many different source both from within the MediaWiki community as well as the broader industry. If you have a code health topic that you’d like to share, please let us know.
We plan to hold office hours.
For code health to really improve, we need to engage as a community, like we do for so many other things, and that involves regular communication.
Although we will fully expect and support ad hoc discussions to happen, we thought it might enable those discussions if we had some “office hours” where folks can gather on a regular basis to ask questions, share experiences, and just chat about code health.
These office hours will be held in IRC as well as a Google Hangout. Choose your preferred tech and swing on by. Check out the CHG Wiki page for more info.
What’s next?
Though the CHG is in a nascent stage, we’re happy with the progress we’ve made. We’re also excited about where we plan to go next.
One of the first areas we plan to focus on is identifying technical debt. Technical debt—which I’ll discuss in an upcoming series of posts—is closely aligned with code health. The newly launched Technical Debt Program will live within the Code Health Group umbrella. We believe that a significant portion of Technical Debt on MediaWiki is due to code health challenges. The technical debt reduction activities will help build sound code health practices that we will then be able to use to avoid incurring additional technical debt, and reducing what currently exists.
Over the coming weeks, we will be releasing a series of blog post on Technical Debt. This will be followed by a broader series of blog posts related to code health. As the code health hub, we’ll also share what we learn from the broader world. In the meantime, please don’t hesitate to reach out to us.
Jean-Rene Branaa, Senior QA Analyst, Release Engineering
Wikimedia Foundation
Thank you to Melody Kramer, Communications, for editing this post.
How Technical Collaboration is bringing new developers into the Wikimedia movement
A Wikimedia team won the Open Minds Award in the category “Diversity” for their work with a mentoring program during the 2017 Wikimedia Hackathon in Vienna. Photo by Jean-Frédéric, CC0/public domain.
The Technical Collaboration team at the Wikimedia Foundation are focusing our efforts on a single goal: recruiting and retaining new volunteer developers to work on Wikimedia software projects.
Onboarding new developers, and ensuring they are set up to succeed, is key to ensuring the long-term sustainability of the Wikimedia developer community, which works on projects seen by billions of people around the world.
The current active developer community, which currently numbers in the hundreds, helps maintain more than 300 code repositories and makes more than 15,000 code contributions on a monthly basis. That puts the Wikimedia projects on par with some of the largest and most active free software development projects in the world, like the Linux kernel, Mozilla, Debian, GNOME, and KDE, among others.
But the developer community is not growing at the pace required to ensure the long-term health of our projects. Conscious of this, the Technical Collaboration team is focusing on bringing in new volunteer developers, connecting them with existing communities, and ensuring the success of both new and experienced technical members of the Wikimedia movement.
What we’re doing
Thinking closely about the ways we conduct outreach through formal programs.
We have participated in the developer training programs Google Summer of Code for 12 years and Outreachy, run by the Software Freedom Conservancy, for 10 rounds over 5 years. Part of our goal in working with those programs is to find and train new developers who continue to contribute to our projects once they complete the internship program. To improve the retention figures, we pair developers in the program with an experienced technical mentor who shares their interest. We are also thinking carefully about the social component of the program, and in helping developers find new challenges and roles after their internships end.
Thinking about the ways in which Wikimedia hackathons and technical events can bring in new developers.
We have changed our approach at Wikimedia hackathons and in technical spaces in order to focus on new developers’ outreach and retention. In the last editions of the Wikimedia Hackathon and the Hackathon at Wikimania, we put more attention towards supporting new developers specifically, by pairing them with mentors and creating spaces specifically for them on-wiki and in-person. We have also promoted smaller regional hackathons to reach out to more developers, and we have modified our scholarship processes so that top newcomers from a local event have a better chance to end up joining our global events.
Where we plan to go next.
Outreach programs and developer events were obvious places to start our work because they already are touch points with outside developers. However, it is also clear that in order to improve our retention of new developers, we have to pursue a variety of approaches. Here are some of the avenues we plan to focus on from our annual plan:
An explicit focus on diversity. We believe that diversity is an intrinsic strength in our developer community. We want to improve our outreach and support to identify developers from around the globe, invite them to join our community, and support them.
Quantitative and qualitative research. Most of our current knowledge and assumptions are not based on systematic research. We plan to focus on some key progress indicators to ensure that we are meeting our goals. Metrics include the number of current volunteer developers, number of new volunteer developers who joined our project over the last quarter, and the number of new developers who remain active after one year. We are also starting to survey all newcomers who contribute a first code patch, and we planto survey new developers who seem to have left the projects. We want to learn more about their initial motivations and the first obstacles they faced, and also about the factors that influenced their decision to leave. We are going to compile the data, findings and lessons learned in a quarterly report.
Featured projects for newcomers. We have been trying to connect potential new developers with any of the hundreds of Wikimedia projects, when in reality, the vast majority of them are not a good destination for volunteers. Many projects are inactive, and others are so active that the learning curve is rather complex. Still others don’t have mentors available or appropriate documentation. To help new developers succeed, we have decided to select a reasonable amount of projects that are ready to welcome newcomers, and we work closely with their mentors to lead newcomers to those areas—to see if this helps improve retention.
Multilingual documentation and support. Picking a limited set of featured projects also helps us support documentation in multiple languages for those projects. We have also thought about the pathways that we want new users to take. While we have traditionally sent new developers to read How to become a MediaWiki hacker, this may not be the right approach if developers want to contribute to tools, bots, gadgets, mobile apps. We are now refreshing our developer documentation for newcomers, and plan to refresh the org homepage accordingly. We also plan to offer one support channel for new developers easy to find and maintain.
By connecting all these pieces, we aim to attract more developers from diverse backgrounds, and to offer pathways into our movement—professionally and personally—that motivate them to stick around.
For many of us, joining the Wikimedia movement was a life-changing experience. We want to help new developers (and their mentors!) walk their own paths in Wikimedia, to gain experience and contacts in our unique community of communities. We want to offer them opportunities to become local heroes fixing technical problems and creating missing features for the Wikimedia communities living in their regions or speaking their languages. We want to offer them opportunities to meet peers across borders and boundaries, working on volunteer or funded projects and traveling to developer events.
We plan to bring the Wikimedia technical community to the levels that one would expect from one of the biggest and most active free software projects, from probably the most popular free content creation project. The chances to succeed depend heavily on current Wikimedia developers (volunteers or professionals) willing to share some of their experience and motivation mentoring newcomers. It also depends heavily on Wikimedia chapters and other affiliates willing to scratch their own technical itches working with us, co-organizing local or thematic developer activities with our help. The first experiments have been very positive (and fun) so far. Join us for more!
Quim Gil, Senior Manager, Technical Collaboration
Wikimedia Foundation
Automated OpenStack Testing, now with charts and graphs
One of our quarterly goals was "Define a metric to track OpenStack system availability". Despite the weak phrasing, we elected to not only pick something to measure but also to actually measure it.
I originally proposed this goal based on the notion that VPS creation seems to break pretty often, but that I have no idea how often, or for how long. The good news is that several months ago Chase wrote a 'fullstack' testing tool that creates a VM, checks to see if comes up, makes sure that DNS and puppet work, and finally deletes the new VM. That tool is now running in an (ideally) uninterrupted loop, reporting successes and failures to graphite so that we can gather up long-term statistics about when things are working.
In addition to the fullstack test, I wrote some Prometheus tests that check whether or not individual public OpenStack APIs are responding to requests. When these services go down the fullstack test is also likely to break, but other things are affected as well: Horizon, the openstack-browser, and potentially various internal Cloud Services things like DNS updates.
All of these new stats can now be viewed on the WMCS API uptimes dashboard. The information there isn't very detailed but should be useful to the WMCS staff as we work to improve stability, and should be useful to our users when they want to answer the question "Is this broken for everyone or just for me?"
*.analytics.db.svc.eqiad.wmflabs (batch jobs; long queries)
Replace * with either a shard name (e.g. s1) or a wikidb name (e.g. enwiki).
The new servers do not support user created databases/tables because replication can't be guaranteed. See T156869 and below for more information. tools.db.svc.eqiad.wmflabs (also known as tools.labsdb) will continue to support user created databases and tables.
Report any bugs you find with these servers in Phabricator using the Data-Services tag.
Wiki Replicas
The Wiki Replicas are one of the unique services that Wikimedia Cloud Services helps make available to our communities. Wiki Replicas are real-time replicas of the production Wikimedia MediaWiki wiki databases with privacy-sensitive data removed. These databases hold copies of all the metadata about content and interactions on the wikis. You can read more about these databases on Wikitech if you are unfamiliar with their details.
The current physical servers for the <wiki>_p Wiki Replica databases are at the end of their useful life. Work started over a year ago on a project involving the DBA team and cloud-services-team to replace these aging servers (T140788). Besides being five years old, the current servers have other issues that the DBA team took this opportunity to fix:
No way to give different levels of service for realtime applications vs analytics queries
No automatic failover to another server when one failed
Bigger, faster, more available
Each of the three new servers is much larger and faster than the servers they are replacing. Five years is a very long time in the world of computer hardware:
We have also upgraded the database software itself. The new servers are running MariaDB version 10.1. Among other improvements, this newer database software allows us to use a permissions system that is simpler and more secure for managing the large number of individual tools that are granted access to the databases.
The new servers use InnoDB tables rather than the previous TokuDB storage. TokuDB was used on the old servers as a space-saving measure, but it has also had bugs in the past that caused delays to replication. InnoDB is used widely in the Wikimedia production databases without these problems.
The new cluster is configured with automatic load balancing and failover using HAProxy. All three hosts have identical data. Currently, two of the hosts are actively accepting connections and processing queries. The third is a ready replacement for either of the others in case of unexpected failure or when we need to do maintenance on the servers themselves. As we learn more about usage and utilization on these new hosts we can change things to better support the workloads that are actually being generated. This may include setting up different query duration limits or pooling the third server to support some of the load. The main point is that the new system provides us with the ability to make these types of changes which were not possible previously.
Improved replication
The work of scrubbing private data is done on a set of servers that we call "sanitarium" hosts. The sanitarium servers receive data from the production primary servers. They then in turn act as the primary servers which are replicated to the Wiki Replica cluster. The two sanitarium servers for the new Wiki Replica cluster use row-based replication (RBR). @Marostegui explains the importance of this change and its relationship to T138967: Labs database replica drift:
[W]e are ensuring that whatever comes to those hosts (which are, in some cases, normal production slaves) is exactly what is being replicated to the [Cloud] servers. Preventing us from data drifts, as any data drift on row based replication would break replication on the [Cloud] servers. Which is bad, because they get replication broken, but at the same time is good, because it is a heads up that the data isn't exactly as we have it in core. Which allows us to maintain a sanitized and healthy dataset, avoiding all the issues we have had in the past.
The data replicated to the new servers has been completely rebuilt from scratch using the RBR method. This has fixed many replication drift problems that exist on the older servers (T138967). If your tool performs tasks where data accuracy is important (counting edits, checking if a page has been deleted, etc), you should switch to using the new servers as soon as possible.
New service names
Populating the new sanitarium servers with data was a long process (T153743), but now that it is done our three new Wiki Replica servers are ready for use. With the old setup, we asked people to use a unique hostname with each database they connected to (e.g. enwiki.labsdb). The new cluster extends this by adding using service names to separate usage by the type of queries that are being run:
Use *.web.db.svc.eqiad.wmflabs for webservices and other tools that need to make small queries and get responses quickly.
Use *.analytics.db.svc.eqiad.wmflabs for longer running queries that can be slower.
If you were using enwiki.labsdb you should switch to either enwiki.analytics.db.svc.eqiad.wmflabs or enwiki.web.db.svc.eqiad.wmflabs. The choice of "analytics" or "web" depends on what your tool is doing, but a good rule of thumb is that any query that routinely takes more than 10 seconds to run should probably use the "analytics" service.
Right now there is no actual difference between connecting to the "web" or "analytics" service names. As these servers get more usage and we understand the limitations they have this may change. Having a way for a user to explicitly choose between real-time responses and slower responses for more complicated queries will provide more flexibility in tuning the systems. We expect to be able to allow queries to run for a much longer time on the new analytics service names than we can on the current servers. This in turn should help people who have been struggling to gather the data needed for complex reports within the current per-request timeout limits.
A breaking change
These new servers will not allow users to create their own databases/tables co-located with the replicated content. This was a feature of the older database servers that some tools used to improve performance by making intermediate tables that could then be JOINed to other tables to produce certain results.
We looked for solutions that would allow us to replicate user created data across the three servers, but we could not come up with a solution that would guarantee success. The user created tables on the current servers are not backed up or replicated and have always carried the disclaimer that these tables may disappear at any time. With the improvements in our ability to fail over and rebalance traffic under load, it is more likely on the new cluster that these tables would randomly appear and disappear from the point of view of a given user. This kind of disruption will break tools if we allow it. It seems a safer solution for everyone to disallow the former functionality.
User created databases and tables are still supported on the tools.db.svc.eqiad.wmflabs server (also known as tools.labsdb). If you are using tables co-located on the current c1.labsdb or c3.labsdb hosts we are recommending that your tool/scripts be updated to instead keep all user managed data on tools.db.svc.eqiad.wmflabs and perform any joining of replica data and user created data in application space rather than with cross-database joins.
There will be further announcements before the old servers are completely taken offline, but tools maintainers are urged to make changes as soon as they can. The hardware for the older servers is very old and may fail in a non-recoverable way unexpectedly (T126942).
Curated datasets
There are some datasets produced by ORES, the Analytics team, or volunteers that really do need to be co-located with the wiki tables to be useful. We are looking for a solution for these datasets that will allow them to be replicated properly and available everywhere. See T173511: Implement technical details and process for "datasets_p" on wikireplica hosts for further discussion of providing some method for 'curated' datasets to be added to the new cluster.
Quarry will be switched over to use *.analytics.db.svc.eqiad.wmflabs soon. As noted previously, using the analytics service names should allow more complex queries to complete which will be a big benefit for Quarry's users who are doing analytics work. This change may however temporarily interrupt usage of some datasets that are blocked by T173511. Follow that task for more information if your work is affected.
You can help test the new servers
Before we make the new servers the default for everyone, we would like some early adopters to use them and help us find issues like:
*.analytics.db.svc.eqiad.wmflabs (batch jobs; long queries)
Replace the * with either a shard name (e.g. s1) or a wikidb name (e.g. enwiki).
For interactive queries, use one of:
sql --cluster analytics <database_name>
mysql --defaults-file=$HOME/replica.my.cnf -h <wikidb>.analytics.db.svc.eqiad.wmflabs <database_name>
Report any bugs you find with these servers and their data in Phabricator using the Data-Services tag.
Thanks
The cloud-services-team would like to especially thank @jcrespo and @Marostegui for the work that they put into designing and implementing this new cluster. Without their technical experience and time this project would never have been successful.
24% of Wikipedia edits over a three month period in 2016 were completed by software hosted in Cloud Services projects. In the same time period, 3.8 billion Action API requests were made from Cloud Services. We are the newly formed Cloud Services team at the Foundation, which maintains a stable and efficient public cloud hosting platform for technical projects relevant to the Wikimedia movement. -- https://blog.wikimedia.org/2017/09/11/introducing-wikimedia-cloud-services/
With a lot of help from @MelodyKramer and the Wikimedia-Blog team, we have published a blog post on the main Wikimedia blog. The post talks a bit about why we formed the Wikimedia Cloud Services team and what the purpose of the product rebranding we have been working on is. It also gives a shout out to a very small number of the Toolforge tools and Cloud VPS projects that the Wikimedia technical community make. I wish I could have named them all, but there are just too many!
Toolsadmin.wikimedia.org is a management interface for Toolforge users. On 2017-08-24, a new major update to the application was deployed which added support for creating new tool accounts and managing metadata associated with all tool accounts.
Under the older Wikitech based tool creation process, a tool maintainer sees this interface:
As @yuvipanda noted in T128158, this interface is rather confusing. What is a "service group?" I thought I just clicked a link that said "Create a new Tool." What are the constrains of this name and where will it be used?
With the new process on toolsadmin, the initial form includes more explanation and collects additional data:
The form labels are more consistent. Some explanation is given for how the tool's name will be used and a link is provided to additional documentation on wikitech. More information is also collected that will be used to help others understand the purpose of the tool. This information is displayed on the tool's public description page in toolsadmin:
After a tool has been created, additional information can also be supplied. This information is a superset of the data needed for the toolinfo.json standard used by Hay's Directory. All tools documented using toolsadmin are automatically published to Hay's Directory. Some of this information can also be edited collaboratively by others. A tool can also have multiple toolinfo.json entries to support tools where a suite of functionality is published under a single tool account.
The Striker project tracks bugs and feature ideas for toolsadmin. The application is written in Python3 using the Django framework. Like all Wikimedia software projects, Striker is FLOSS software and community contributions are welcome. See the project's page on wikitech for more information about contributing to the project.
Back in year zero of Wikimedia Labs, shockingly many services were confined to a single box. A server named 'virt0' hosted the Wikitech website, Keystone, Glance, Ldap, Rabbitmq, ran a puppetmaster, and did a bunch of other things.
Even after the move from the Tampa data center to Ashburn, the model remained much the same, with a whole lot of different services crowded onto a single, overworked box. Since then we've been gradually splitting out important services onto their own systems -- it takes up a bit more rack space but has made debugging and management much more straightforward.
Today I've put the final finishing touches on one of the biggest break-away services to date: The puppetmaster that manages most cloud instances is no longer running on 'labcontrol1001'; instead the puppetmaster has its own two-server cluster which does puppet and nothing else. VMs have been using the new puppetmasters for a few weeks, but I've just now finally shut down the old service on labcontrol1001 and cleaned things up.
With luck, this new setup will gain us some or all of the following advantages:
fewer bad interactions between puppet and other cloud services: In particular, RabbitMQ (which manages most communication between openstack services) runs on labcontrol1001 and is very hungry for resources -- we're hoping it will be happier not competing with the puppetmaster for RAM.
improved puppetmaster scalability: The new puppetmaster has a simple load-balancer that allows puppet compilations to be farmed out to additional backends when needed.
less custom code: The new puppetmasters are managed with the same puppet classes that are used elsewhere in Wikimedia production.
Of course, many instances weren't using the puppetmaster on labcontrol1001 anyway; they use separate custom puppetmasters that run directly on cloud instances. In many ways this is better -- certainly the security model is simpler. It's likely that at some point we'll move ALL puppet hosting off of metal servers and into the cloud, at which point there will be yet another giant puppet migration. This last one went pretty well, though, so I'm much less worried about that move than I was before; and in the meantime we have a nice stable setup to keep things going.
Toolforge provides proxied mirrors of cdnjs and now fontcdn, for your usage and user-privacy
Tool owners want to create accessible and pleasing tools. The choice of fonts has previously been difficult, because directly accessing Google's large collection of open source and freely licensed fonts required sharing personally identifiable information (PII) such as IPs, referrer headers, etc with a third-party (Google). Embedding external resources (fonts, css, javascript, images, etc) from any third-party into webpages hosted on Toolforge or other Cloud VPS projects causes a potential conflict with the Wikimedia Privacy Policy. Web browsers will attempt to load the resources automatically and this will in turn expose the user's IP address, User-Agent, and other information that is by default included in an HTTP request to the third-party. This sharing of data with a third-party is a violation of the default Privacy Policy. With explict consent Toolforge and Cloud VPS projects can collect and share some information, but it is difficult to secure that consent with respect to embedded resources.
One way to avoid embedding third-party resources is for each Tool or Cloud VPS project to store a local copy of the resource and serve it directly to the visiting user. This works well from a technical point of view, but can be a maintenance burden for the application developer. It also defeats some of the benefits of using a content distribution network (CDN) like Google fonts where commonly used resources from many applications can share a single locally cached resource in the local web browser.
Since April 2015, Toolforge has provided a mirror of the popular cdnjs library collection to help Toolforge and Cloud VPS developers avoid embedding javascript resources. We did not have a similar solution for the popular Google Fonts CDN however. To resolve this, we first checked if the font files are available via bulk download anywhere, sort of like cdnjs, but they were not. Instead, @zhuyifei1999 and @bd808 have created a reverse proxy and forked a font-searching interface to simplify finding the altered font CSS URLs. You can use these features to find and use over 800 font families.
The shared Elasticsearch cluster hosted in Toolforge was upgraded from 2.3.5 to 5.3.2 today (T164842). This upgrade comes with a lot of breaking API changes for clients and indexes, and should have been announced in advance. @bd808 apologizes for that oversight.
The stashbot, sal, and bash tools have been fixed to work with the new version. They all mostly needed client library upgrades and minor API usage changes due to the library changes. If you are one of the few other users of this cluster and your tool is broken due to the change and you need help fixing it, open a task or better yet come to the #wikimedia-cloud Freenode channel and ask @bd808 for help.
This new team will soon begin working on rebranding efforts intended to reduce confusion about the products they maintain. This refocus and re-branding will take time to execute, but the team is looking forward to the challenge.
In May we announced a consultation period on a straw dog proposal for the rebranding efforts. Discussion that followed both on and off wiki was used to refine the initial proposal. During the hackathon in Vienna the team started to make changes on Wikitech reflecting both the new naming and the new way that we are trying to think about the large suite of services that are offered. Starting this month, the changes that are planned (T168480) are becoming more visible in Phabricator and other locations.
It may come as a surprise to many of you on this list, but many people, even very active movement participants, do not know what Labs and Tool Labs are and how they work. The fact that the Wikimedia Foundation and volunteers collaborate to offer a public cloud computing service that is available for use by anyone who can show a reasonable benefit to the movement is a surprise to many. When we made the internal pitch at the Foundation to form the Cloud Services team, the core of our arguments were the "Labs labs labs" problem and this larger lack of awareness for our Labs OpenStack cluster and the Tool Labs shared hosting/platform as a service product.
The use of the term 'labs' in regards to multiple related-but-distinct products, and the natural tendency to shorten often used names, leads to ambiguity and confusion. Additionally the term 'labs' itself commonly refers to 'experimental projects' when applied to software; the OpenStack cloud and the tools hosting environments maintained by WMCS have been viable customer facing projects for a long time. Both environments host projects with varying levels of maturity, but the collective group of projects should not be considered experimental or inconsequential.
Debian Stretch was officially released on Saturday[1], and I've built a new Stretch base image for VPS use in the WMF cloud. All projects should now see an image type of 'debian-9.0-stretch' available when creating new instances.
Puppet will set up new Stretch instances just fine, and we've tested and tuned up several of the most frequently-used optional puppet classes so that they apply properly on Stretch. Stretch is /fairly/ similar to Jessie, so I'd expect most puppet classes that apply properly on Jessie to work on Stretch as well, but I'm always interested in the exceptions -- If you find one, please open a phabricator ticket.
The WMF and the Cloud team is committed to long-term support of this distribution. If you are starting a new project or rebuilding a VM you should start with Stretch to ensure the longest possible life for your work.
Watroles returns! (In a different place and with a different name and totally different code.)
Back in the dark ages of Labs, all instance puppet configuration was handled using the puppet ldap backend. Each instance had a big record in ldap that handled DNS, puppet classes, puppet variables, etc. It was a bit clunky, but this monolithic setup allowed @yuvipanda to throw together a simple but very useful tool, 'watroles'. Watroles answered two questions:
What puppet roles and classes are applied to a given instance?
What instances use a given puppet class or role?
#2 turned out to be especially important -- basically any time an Op merged a patch changing a puppet role, they could look at watroles to get a quick list of all the instances that were going to break. Watroles was an essential tool for keeping VMs properly puppetized during code refactors and other updates.
Alas, the puppet ldap backend fell into disrepair. Puppetlabs stopped maintaining it, and Labs VMs were left out of more and more fancy puppet features because those features were left out of ldap. So... we switched to a custom API-based puppet backend, one that talks to Horizon and generally makes VM puppet config more structured and easier to handle (as well as supporting project-wide and prefix-wide puppet config for large-scale projects.)
That change broke Watroles, and the tool became increasingly inaccurate as instances migrated off of ldap, and eventually it was turned off entirely. A dark age followed, in which puppet code changes required as much faith as skill.
Today, at last, we have a replacement. I added a bunch of additional general-purpose queries to our puppet configuration API, and we've added pages to the OpenStack Browser to display those queries and answer both of our previous questions, with bonus information as well:
The data on those pages is cached and updated every 20 minutes, so won't update instantly when a config is changed, but should nonetheless provide all the information needed for proper testing of new code changes.
#wikimedia-labs irc channel renamed to #wikimedia-cloud
The first very visible step in the plan to rename things away from the term 'labs' happened around 2017-06-05 15:00Z when IRC admins made the #wikimedia-labs irc channel on Freenode invite-only and setup an automatic redirect to the new #wikimedia-cloud channel.
If you were running a bot in the old channel or using an IRC bouncer like ZNC with "sticky" channel subscriptions you may need to make some manual adjustments to your configuration.
Kubernetes webservices will need to be restarted to pick up the new Docker images with the updated package installed. The new Docker images also contain the latest packages from the upstream apt repositories which may provide some minor bug fixes. We are not currently tracking the exact versions of all installed packages, so we cannot provide a detailed list of the changes.
When @Ryan_Lane first built OpenStackManager and Wikitech, one of the first features he added was an interface to setup project-wide sudo policies via ldap.
I've basically never thought about it, and assumed that no one was using it. A few months ago various Labs people were discussing sudo policies and it turned out that we all totally misunderstood how they worked, thinking that they derived from Keystone roles rather than from a custom per-project setup. I immediately declared "No one is using this, we should just rip out all that code" and then ran a report to prove my point... and I turned out to be WRONG. There are a whole lot of different custom sudo policies set up in a whole lot of different projects.
So... rather than ripping out the code, I've implemented a new sudo interface that runs in Horizon. [T162097] It is a bit slow, and only slightly easier to use than the old OpenStackManager interface, but it gets us one step closer to moving all PVS user interfaces to Horizon. [T161553]
For the moment, users can edit the same policies either on Horizon or on Wikitech. If I don't get complaints then I'll remove the UI from wikitech in a few weeks.
For nearly a year, Horizon has supported instance management. It is altogether a better tool than the Special:NovaInstance page on Wikitech -- Horizon provides more useful status information for VMs, and has much better configuration management (for example changing security groups for already-running instances.)
So... I've just now removed the sidebar 'Manage Instances' link on Wikitech, and will shortly be disabling the Special:NovaInstance page as well. This is one more (small) step down the road to standardizing on Horizon as the one-stop OpenStack management tool.
I've just installed a new public base image, ' debian-9.0-stretch (experimental)' and made it available for all projects. It should appear in the standard 'Source' UI in Horizon any time you create a new VM.
Please take heed of the word 'experimental' in the title. Stretch is not yet an official Debian release, and may still contain unexpected bugs and security issues. Additionally, the operations puppet repo has only begun to be Stretch-aware, so many roles and classes will likely fail or engage in otherwise undefined behavior.
So...
Please DO use this image to test and update puppet classes, and to get a preview of things to come.
Please DO NOT use this image to build any instances that you plan to expose to the public, or that you want to keep around for more than a few months.
When Stretch is officially released and we've ironed out some more puppet issues I will delete this base image and purge those VMs that were built from it in order to avoid the debt of having to support 'experimental' VMs for eternity.
Labs Openstack upgrade on Tuesday, 2016-08-02, 16:00 UTC
Andrew will be upgrading our Openstack install from version 'Kilo' to version 'Liberty' on Tuesday the 2nd. The upgrade is scheduled to take up to three hours. Here's what to expect:
Tools services and existing Labs uses should be unaffected apart from brief ( < 1 minute) interruptions in network service.
Continuous Integration tests (Jenkins, Zuul, etc.) will be disabled for most of the upgrade window.
Creation/Deletion of new instances will be disabled for most of the window.
Wikitech and Horizon may error out occasionally and/or display inconsistent information. Users may need to refresh their web logins after the upgrade.
Apart from fixing a few seldom-seen bugs, this upgrade shouldn't result in noticeable changes for Labs users. It will lay the groundwork for an upcoming Horizon upgrade, but that will be announced in future posts/emails.
If you are exclusively a user of tool labs, you can ignore this post. If you use or administer another labs project, this REQUIRES ACTION ON YOUR PART.
We are reclaiming unused resources due to an ongoing shortage.
Visit this page and add a signature under projects you know to be active:
Associated wmflabs.org domains are included to identify projects by offered services.
We are not investigating why projects are needed at this time. If one person votes to preserve then we will do so in this round of cleanup.
In a month, projects and associated instances not claimed will be suspended or shutdown. A month later if no one complains these projects will be deleted.
Kubernetes Webservice Backend Available for PHP webservices
The Kubernetes ('k8s') backend for Tool Labs webservices is open to
beta testers from the community as a replacment for Grid Engine
(qsub/jsub).
We have focused on providing support for PHP webservices with other
job types to follow. No action is required for users who do not want
to change at this time.
Advantages:
Debian Jessie
PHP (5.6)
Better isolation between tools
Testing the future platform and helping Tool Labs mature
How to switch an existing webervice to the Kubernetes backend:
The Wikimedia Legal team is interested in revising, updating, and clarifying the existing Labs Terms of Use governing developers and their projects on labs.
We have opened up Round 1 of our community consultation to hear feedback on the Labs Terms of Use. We will try to respond the best we can, but the main purpose of this round is to hear all your thoughts. After the feedback round, we will prepare a draft revision of the Terms based on that feedback and other minor revisions to clarify statements in existing the Terms. We will then engage in a community discussion about the revised Terms.
We plan to leave the discussion open until June 9, 2016.
horizon (OpenStack Dashboard) is the canonical implementation of OpenStack’s Dashboard, which provides a web based user interface to OpenStack services.
Horizon requires 2fa to manage project resources. 2fa (which has long been required of all wikitech admins) can be setup on your special preferences page.
tools-login.wmflabs.org is on a new bastion host with twice
the RAM and CPU of the old one. This should hopefully provide a better
bandaid against it getting overloaded up. More discussion about a
longer term solution at https://phabricator.wikimedia.org/T131541
On Tuesday, 2016-04-05, we'll be upgrading Kubernetes to 1.2 and using
a different deployment method as well. While this should have no user
facing impact (ideally!) the following things might be flaky for a
period of time on that day:
In the previous part of this tutorial, we walked through how to make a very basic version of a ToDo app using Wikimedia’s OOjs UI library. Now it’s time to add a way to store and display information from our items.
This post and the accompanying code is available on Github. Corrections and pull requests are welcome!
Displaying info
Let’s first create a way to view the information we have about our items. We’ll start by adding a simple label to our page:
$( document ).ready( function () {
var input = new OO.ui.TextInputWidget( {
placeholder: 'ToDo item',
classes: [ 'todo-input' ]
} ),
list = new OO.ui.SelectWidget( {
classes: [ 'todo-list' ]
} ),
info = new OO.ui.LabelWidget( {
label: 'Information',
classes: [ 'todo-info' ]
} );
// ... code ...
// Append the app widgets
$( '.wrapper' ).append(
input.$element,
list.$element,
info.$element
);
} );
Once again, we’re adding a widget, and appending its $element to the DOM. Now we can use it to display the information stored in our widget. The ToDo items all live inside an OO.ui.SelectWidget which emits a ‘choose’ event when an element is clicked or chosen, with the reference to the chosen item as the parameter. We’ll attach a listener to this event.
Now we have a very simple way of presenting the data stored in our item. This is a good start, but it doesn’t yet seem to be all that helpful, because the data stored in each of our items is the same as its label, and doesn’t quite give us any useful information. Let’s change that now.
Creating a custom item widget
In order to expand the functionality of the OO.ui.OptionWidget so we can store more information, we need to create our own class and extend OO.ui.OptionWidget.
Create a new file in your assets/ directory, called assets/ToDoItemWidget.js. In it, we are creating our new class:
Our new function extends OO.ui.OptionWidget, by declaring OO.inheritClass( ToDoItemWidget, OO.ui.OptionWidget ); and by calling the parent constructor in the new class’ constructor.
Before we start actually defining members of this class, let’s make sure we can use it in our code. Let’s reopen index.html again.
First, add the file:
Second, change the code to use the new ToDoItemWidget class:
$( document ).ready( function () {
// ... code ...
// Respond to 'enter' keypress
input.on( 'enter', function () {
// ... code ...
// Add the item
list.addItems( [
new ToDoItemWidget( {
data: input.getValue(),
label: input.getValue()
} )
] );
} );
// ... code ...
} );
You can try out your app again, but nothing should be different just yet. We can now start developing our new class to add the functionality we want to have.
Adding functionality
Let’s add a property that stores the creation time of our todo item.
But we’re not done. We’ve already enhanced the items, so let’s add some real functionality in there.
Adding a ‘delete’ button to items
Another of OOjs UI’s concepts is componentization – the ability to create bigger widgets from smaller ones. This can be pretty powerful and allow for advanced functionality.
We’re going to start small. Let’s add a ‘delete’ button to our list of items. You can read about what OO.ui.ButtonWidget expects in its configuration options in the official documentation.
In our ToDoItemWidget.js we’ll add a button:
var ToDoItemWidget = function ( config ) {
// ... code ...
this.deleteButton = new OO.ui.ButtonWidget( {
label: 'Delete'
} );
this.$element.append( this.deleteButton.$element );
};
Just like any other widget in OOjs UI, OO.ui.ButtonWidget has the $element property that contains its jQuery object. We’re attaching that to our own widget.
If you look at your app now, though, you’ll see that the button appears under the label. That’s because we need to add styles. Since we’re building our own widget, let’s do things properly and add a standalone style for it that we can then add and tweak in our CSS rules.
var ToDoItemWidget = function ( config ) {
// ... code ...
this.deleteButton = new OO.ui.ButtonWidget( {
label: 'Delete'
} );
this.$element
.addClass( 'todo-itemWidget' )
.append( this.deleteButton.$element );
};
There, that looks better. Now, let’s add functionality to this button.
Aggregating events
One of the best things about using a OO.ui.SelectWidget for our list, is that it uses the OO.ui.mixin.GroupElement that allows for really cool operations on a group of items.
One of those operations is an aggregation of events.
In effect, we can have each of our items emit a certain event, and have our list aggregate all of those events and respond whenever any of its items have emitted it. This means our logic can live “up” in the parent widget, consolidating our work with our items.
This means, however, that we will need to enhance our list object. We are going to do exactly what we did for our items (by creating the ToDoItemWidget class) but with a new ToDoListWidget class that extends OO.ui.SelectWidget.
Notice that this time, we didn’t use .on( ... ) but rather .connect( this, { ... } ) – this is because we are now connecting the object we are currently “in” the context of, to the event. I’ve used “on” before when we were in the general initialization script, and had no context to give the event emitter.
The string ‘onDeleteButtonClick’ refers to the method of the same name. When ‘click’ is emitted from that button, that method is invoked. It, in turn, will emit “delete” event.
Now, we need to make sure that the list is listening to this event from all of its sub-items. We will first aggregate the event and then listen to the aggregated event and respond to it:
We’ve used this.aggregate() to tell the group which events to listen to in its items, and we’ve used this.connect( this, { ... } ); to connect our own object to the event we aggregated.
Then, the responding method (onItemDelete) removes the item from the list.
You can now add and remove items from your ToDo app, yay!
The complete code
$( document ).ready( function () {
var input = new OO.ui.TextInputWidget( {
placeholder: 'ToDo item',
classes: [ 'todo-input' ]
} ),
list = new ToDoListWidget( {
classes: [ 'todo-list' ]
} ),
info = new OO.ui.LabelWidget( {
label: 'Information',
classes: [ 'todo-info' ]
} );
// Respond to 'enter' keypress
input.on( 'enter', function () {
// Check for duplicates
if ( list.getItemFromData( input.getValue() ) ) {
input.$element.addClass( 'todo-error' );
return;
}
input.$element.removeClass( 'todo-error' );
// Add the item
list.addItems( [
new ToDoItemWidget( {
data: input.getValue(),
label: input.getValue(),
creationTime: Date.now()
} )
] );
} );
list.on( 'choose', function ( item ) {
info.setLabel( item.getData() + ' (' + item.getPrettyCreationTime() + ')' );
} );
// Append the app widgets
$( '.wrapper' ).append(
input.$element,
list.$element,
info.$element
);
} );
Future development and tutorials
Now that the app has basic operations, we can call this part of the tutorial over. I hope that you got a good taste as to what OOjs UI is like, and the potential it holds in quickly – but efficiently – developing JavaScript apps.
If you have any questions, concerns or corrections, please let me know in the comments. The entire code for this demo – and the text of the tutorials – is available in a GitHub repo, and pull requests are absolutely welcome.
In the next tutorials I will focus on the more advanced features of OOjs UI, like dialogs, advanced button-sets and working with a view-model to help us manage the operations in the background.
In this post we’ll walk through creating a simple ToDo JavaScript app with the OOjs UI library, which was created by the Wikimedia Foundation. OOjs UI has a lot of power under the hood and a lot of potential for super-powerful JavaScript applications in your browser — so we will start small and grow as we go, hopefully giving you a taste of the library and its concepts.
This post and the accompanying code is available on Github. Corrections and pull requests are welcome!
OOjs UI itself is licensed under MIT. The code we will create is licensed under GPLv2.
Setup and prep
First, we’ll have to get the libraries we will use: jQuery, OOjs and OOjs UI.
Libraries
In your project directory, create a assets/lib/ folder that will hold our necessary libraries:
OOjs and OOjs UI are available from the official repositories, and there are two ways to download the files we need (see next section).
There are two main ways to get the files for both of these libraries, depending on how comfortable you are with development environment and working with git.
Getting OOjs and OOjs UI from the git repo
If you’re comfortable with git and gruntjs, this is the best way to work with OOjs and OOjs UI library files, as those will give you the most updated files each time:
Run npm install in each of the repositories to install the necessary packages.
Run grunt build in each of the repositories. This will populate their dist/ folders, which is where you get the library files to use.
For OOjs, we will use the oojs.jquery.js file (place that one in your assets/lib folder)
OOjs UI is a robust library with the option of separating modules. We don’t need most of the files in the dist/ folder, all we need are these files to be copied files into your assets/lib/ooui/ folder:
dist/oojs-ui.min.js
dist/oojs-ui-apex.min.js
dist/oojs-ui-apex.css
dist/themes/apex
Getting OOjs and OOjs UI from the demo zip
If you don’t want to mess with git and grunt, you can download the demo files and extract the necessary library files directly from it, trusting that I did the job for you.
The only caveat here is that the demo zip will likely not be updated as often as OOjs UI is updated, so be advised that you may be using an older library version.
Project files
We will start with two files for our project – the JavaScript initialization file and the CSS file.
todo.css – Create an empty file todo.css and place it in the main directory – we will use this file later for all of our custom CSS styling.
assets/init.js – Create a new empty file init.js and place it in the assets/ directory. This will be our initialization script.
Add to the project
Next, we will attach those files to our html page. This is how our basic page should look like now:
ToDo OOjs UI
Demo ToDo app with OOjs UI
We will use the wrapper div element to inject our application into.
Building the base
So now that we have our basic page, we need to start writing code. Our ToDo app should have two main pieces to start with: An input to add a new item, and a list displaying all items that have been added. Since a ToDo list allows us to show a list of items that can be selected, the best starting point for this is an OO.ui.SelectWidget — so that’s what we’ll start with. You can see a demo of all OOjs UI widgets in the official demo page.
$( document ).ready( function () {
var input = new OO.ui.TextInputWiget(),
list = new OO.ui.SelectWidget();
// Append to the wrapper
$( '.wrapper' ).append(
input.$element,
list.$element
);
} );
Let’s break this up and see what we did there.
One of OOjs UI’s principles is to separate the data from the UI, so each one of the widgets we’re creating is first and foremost an object that is separate from the DOM. That object contains the DOM element itself in the $element property, which we use to attach to the document, but the behavior itself (as we will soon see) is done through the general OOjs UI object.
So in short, we created two widgets — a text input and a select widget — and then attached their $element to the document. If you load your page, it should have the title and an input. The list is invisible because we don’t have a way to add elements to it yet — so let’s do that now.
Adding items to the list
We have our input, and we have the list, and now we need to connect them. OO.ui.TextInputWidget emits several events – one of them is simply “enter” when the enter key is pressed (You can see all events in the documentation). Let’s make our input add an item to the list when we hit the “enter” key.
Since the list is an OO.ui.SelectWidget we should add into it an OO.ui.OptionWidget.
// Respond to 'enter' keypress
input.on( 'enter', function () {
// Add the item
list.addItems( [
new OO.ui.OptionWidget( {
data: input.getValue(),
label: input.getValue()
} )
] );
} );
That would add an item to the list. But what if we are trying to add an item that already exists? Let’s add a condition that checks whether the item exists first before it is added:
// Respond to 'enter' keypress
input.on( 'enter', function () {
// Check for duplicates
if ( list.getItemFromData( input.getValue() ) ) {
input.$element.addClass( 'todo-error' );
return;
}
input.$element.removeClass( 'todo-error' );
// Add the item
list.addItems( [
new OO.ui.OptionWidget( {
data: input.getValue(),
label: input.getValue()
} )
] );
} );
We now are able to only add unique items to this list. When an item that already exists is added, we attach the class “todo-error” to the input. For it to actually show something, we need to define it in our CSS file. Add this to your todo.css file:
.todo-error input {
background-color: #FF9696;
}
Now let’s try our new app:
It works! Now, let’s add a little bit of extra flair to the app.
Custom styling
Let’s make sure that our list and our input are styled a bit better, and add a placeholder to the input. Let’s go back to the piece in our code where we created the widgets, and add configuration to both:
$( document ).ready( function () {
var input = new OO.ui.TextInputWiget( {
placeholder: 'ToDo item',
classes: [ 'todo-input' ]
} ),
list = new OO.ui.SelectWidget( {
classes: [ 'todo-list' ]
} );
// code continues...
} );
The above configuration adds CSS classes to the widgets and a placeholder text to the text widget. We can now go edit our todo.css stylesheet, and add styles. Notice that we can also style the underlying objects, which (for now) we will do by calling their oo-ui-style class:
I released the Cargo extension two months ago, though I’m only blogging about it now. (Though I did post about it to mailing lists and so on.) But I also wanted to wait a little while before fully announcing it, because on first release it was somewhat more experimental than it is now, and I wasn’t entirely sure that it would really work at all. But now I can say that it does indeed have users, and it does seem to work without any major security flaws.
Cargo is – though it still feels awkward to say it – intended as an alternative to Semantic MediaWiki. And not just to SMW itself, but to the set of libraries that SMW makes use of, and to many of the extensions that have been built on top of SMW, including Semantic Result Formats and Semantic Drilldown (though not Semantic Forms). All in all, Cargo is meant to serve as a substitute for a group of around 15 MediaWiki extensions; a more complete explanation can be found here.
Cargo can take the place of all of these extensions together, with a significantly smaller set of code, because it has a simplified approach to data storage. Instead of storing data as triples (in standard Semantic Web style), it stores data directly in database tables – it constructs a separate table for each set of data, then allows, more or less, direct SQL “SELECT” calls on those data sets. MediaWiki templates are used to define and store the data – much in the same way that they’re already used for data storage in SMW, though with Cargo it’s done more formally.
Altogether, this approach means that no custom storage or querying mechanism really had to be built for Cargo, unlike with Semantic MediaWiki; instead, the code for storing and querying data is a relatively thin wrapper around SQL, though with enough code to handle security concerns and data structures that are not well supported in most database systems, like fields that hold an array of values.
There are other interesting aspects to Cargo, and the whole issue of storing data in free-form triples vs. in structured tables is a very interesting one – really a philosophical issue. But I’m not going to get into any of that here; there’s a little more about it on the Cargo page. I do want to clarify what this means for WikiWorks. We are a full-service MediaWiki consulting company, which means that we support all manner of MediaWiki customizations and extensions; I look forward to providing support for Semantic MediaWiki installations for a long time. For new MediaWiki installations, I expect that we will be recommending Cargo if there’s ever a need for a data storage component – because it’s easier to set up, use, and maintain than SMW, in my opinion. But the jury’s still out, as they say, on Cargo, and I look forward to seeing what happens with both extensions.
(Though I did post about it to mailing lists and so on.) But I also wanted to wait a little while before fully announcing it, because on first release it was somewhat more experimental than it is now, and I wasn’t entirely sure that it would really work at all. But now I can say that it does indeed have users, and it does seem to work without any major security flaws.
Cargo is, though it still feels awkward to say it, intended as an alternative to Semantic MediaWiki. And not just to SMW itself, but to the set of libraries that SMW makes use of, and to many of the extensions that have been built on top of SMW, including Semantic Result Formats and Semantic Drilldown (though not Semantic Forms). All in all, Cargo is meant to serve as a substitute for a group of around 15 MediaWiki extensions; a more complete explanation can be found here.
Cargo can take the place of all of these extensions together, with a significantly smaller set of code, because it has a simplified approach to data storage. Instead of storing data as triples (in standard Semantic Web style), it stores data directly in database tables – it constructs a separate table for each set of data, then allows, more or less, direct SQL “SELECT” calls on those data sets. MediaWiki templates are used to define and store the data – much in the same way that they’re already used for data storage in SMW, though with Cargo it’s done more formally.
Altogether, this approach means that no custom storage or querying mechanism really had to be built for Cargo, unlike with Semantic MediaWiki; instead, the code for storing and querying data is a relatively thin wrapper around SQL, though with enough code to handle security concerns and data structures that are not well supported in most database systems, like fields that hold an array of values.
There are other interesting aspects to Cargo, and the whole issue of storing data in free-form triples vs. in structured tables is a very interesting one – really a philosophical issue. But I’m not going to get into any of that here; there’s a little more about it on the Cargo page. I do want to clarify what this means for WikiWorks. We are a full-service MediaWiki consulting company, which means that we support all manner of MediaWiki customizations and extensions; I look forward to providing support for Semantic MediaWiki installations for a long time. For new MediaWiki installations, I expect that we will be recommending Cargo if there’s ever a need for a data storage component – because it’s easier to set up, use, and maintain than SMW, in my opinion. But the jury’s still out, as they say, on Cargo, and I look forward to seeing what happens with both extensions.
We just released the MultimediaPlayer extension, which plays a list of multimedia files. It is intended for use with multimedia items hosted by an external service – not stored in the wiki.
This is, as far as I know, a different approach to Multimedia that no extension supported. Instead of showing a bunch of multimedia items, such as YouTube video thumbnails, this extension uses one player. It also generates a (usually) text list of items. Clicking on an item loads the player with the correct item.
This presumably provides a performance boost. More importantly, it is a more elegant approach to playing a large number of files. Showing 20 video thumbnails on a page is not so good. It also allows using content from mixed hosts in a way that is pretty hidden from users. Why should the user care whether a video is hosted by YouTube or Vimeo or Uncle Timmy’s? It just needs to play. Items can come from multiple sources and can be a mix of audio and video.
Default sources
By default, the player supports files hosted by DailyMotion, Instagram, SoundCloud, YouTube, Vimeo and Vine. It plays these items by embedding each service’s player. These sources also ship with some CSS that makes the players responsive.
Add your own source
The player is customizable. Admins can add code for an external player. Then that source can be included with the “multimediaitem” parser function call just like any of the default sources.
Example
This was created for the International Anesthesia Research Society and their project openanesthesia.org. You can see it in action here. They are temporarily using a very old version of the extension but the functionality is similar. Most of the items on this page come from Libsyn, and either use Libsyn’s audio or video player.
As time goes on, I’m becoming more and more object-oriented oriented. I’ve never created an extra class and later regretted it (because it blocked some kind of functionality I later wanted to add) and had to remove that class and insert its code into some other class. But the reverse happens to me all the time. So I decided to skip all that and put everything in its own class. The classes used were:
MultimediaPlayer – This defines the player as a whole, interacting with or holding the other classes.
MultimediaPlayerItem – Defines an Item, created by the parser function and displayed to the user as a clickable link that loads a player into the container.
MultimediaPlayerSources – Really a static class that just holds the code for each known source.
The Singleton Pattern
Right now, there can only be on MultimediaPlayer per page. That’s probably not ideal and may change. But it calls for only one instance to be used. So I originally created this by instantiating the MultimediaPlayer as a global. And I knew I would have to fix that. Still, I had trouble with deciding how.
So I went with the Singleton pattern. This is of course controversial but it’s better than using a global. So it’s an improvement. MediaWiki core uses Singletons in a number of places so I don’t feel too guilty, and I can’t think of a better way. Any ideas? Please comment.
About a week ago we had the NYC Enterprise MediaWiki Hackathon, a two-day event that was also the first-ever enterprise MediaWiki hackathon.
What does it mean to be an enterprise MediaWiki hackathon? It means that the focus is on code that’s used by companies and other organizations that have a MediaWiki installation – as opposed to by Wikipedia and the like. In practice, that usually means MediaWiki extensions.
There have certainly been MediaWiki hackathons before – there have been about five every year since 2011 – but the focus in all of them, as far as I know, has been in some way related to Wikipedia, whether it’s the development of core MediaWiki, extensions in use on Wikipedia, tools and gadgets for Wikipedia, the visualization of Wikipedia data, etc. Which is all to the good – but there’s also a need for this other stuff.
We first discussed having an enterprise hackathon at SMWCon in Berlin, last October. There was a good amount of interest expressed at the time; and if we had had the hackathon in Europe, there probably would have been more attendees, just by the nature of things. But an event in the US was easier for me to attend and orgzine, so that’s where we did this first one. I certainly hope we can have one in Europe before too long. (We also talked about naming it a “Create Camp” instead – and there are valid arguments for calling it that – but I stuck with “hackathon” for this one just to keep things simple.)
The event was held at the NYU-Poly incubator, courtesy of Ontodia, a Semantic MediaWiki-using (and -contributing) company based there – big thanks to them.
So, how did it go? Thursday, the first day of the hackathon, coincided with an epic snowstorm that dropped a foot of snow across much of the Northeast. And Friday was Valentine’s Day. And the whole event was pretty last-minute; the dates were only set a month beforehand. So turnout was certainly curtailed; but we managed to get seven people to show up on one or both days, from New York, DC and Boston; which is not bad, I think. Nearly everyone there was a Semantic MediaWiki user, and that was a big focus of the discussion and work.
The single biggest outcome of the hackathon, in my opinion, was a set of changes to Semantic Forms that Cindy Cicalese from MITRE and I worked on, that will allow for easily displaying alias values for dropdowns, radiobuttons and the like. That’s a feature that SF users have been asking about for a long time. We also got a specific Semantic Forms implementation issue resolved; people looked into setting up a semantic triplestore (though the attempt was ultimately unsuccessful); and there were various discussions about large-scale SMW-based data architecture, skinning, and other topics.
What can we learn from all this?
A hackathon doesn’t need to be big. More projects are of course generally better, but we managed to get a bunch of stuff done with our small size. Having a small group helped us in getting free space, which kept costs minimal. And the round-table discussions we had at the beginning, introducing ourselves and talking about the projects we wanted to see done, might have taken a lot more time with a large group. (Or simply have been prohibitive to do.)
It’s good to have people think about what they want to work on ahead of time, and write their ideas on the wiki page. That helps organizers, and participants, try to plan projects out ahead of time, to maximize productivity.
Not all hackathon results are just code – though I’m of two minds about this one. There were some good discussions, and probably necessary ones, about various aspects of organizational MediaWiki usage. In that way, this hackathon resembled the informal part of conferences – the discussions that happen during breaks, over lunch, etc. These are often just as important as the main part of conferences, and at a hackathon you can have those kinds of discussions in a really focused way. (This hackathon was certainly not unique in that respect.) Still, as a developer, I’m focused on creating and improving code, and that to me is the real measurable output of such events. So perhaps it’ll be a while before we know the full outcome of this hackathon. But judging from people’s feedback afterwards, even time spent not writing code was time well spent.
GSoC2013 Summary: Right-to-Left Support in VisualEditor
Published 26 Sep 2013
by Moriel Schottlender
on MediaWiki.
If you’ve read any of my previous posts, you should know by now that I have been participating in the Google Summer of Code internship, working for the Wikimedia Foundation. And now, as the summer has ended, so has this internship, and it’s time for a summary. So here it is in a crunch:
Okay, yeah, this can’t be the real summary, so let me try and summarize this tremendous summer adventure with a bit more content.
Wikimedia Foundation’s VisualEditor
This summer, I worked for the Wikimedia Foundation, which is the organization behind the MediaWiki platform that is the system behind the worldwide Wikipedia websites. More specifically, I worked with the VisualEditor team.
VisualEditor is a highly anticipated upgrade to the way Wikipedia articles can be edited. Ever since MediaWiki (and Wikipedia) was born, editing involved using a special syntax called “Wikitext”. The systax is relatively straight forward: Wrap text with ‘===’ to get a heading, or ”’ to get a bolded text. Start a line with a star (*) for a bullet list or a pound (#) for a numbered list. The idea was to help editors write articles simply without having to know the elaborate functionality of HTML tags.
And for the most part, it worked, rather beautifully, even. It’s all about accessibility; Wikipedia has evolved into the biggest encyclopedia, making it possible for anyone to edit and add to its growing body of knowledge without having any technical know-how.
But as Wikipedia grew in size and in articles became more elaborate, so did wikitext. It evolved to include templates and styles. Wikitext evolved with the community to allow for more and more possibilities and complex usage. Writing articles involved learning a new syntax, and while it was easier than the alternative HTML tags, it still has a learning curve, especially for new users to learn, and even users who are familiar with it sometimes have challenges using it properly. But the biggest issue (at least as far as I am concerned) is using it with right-to-left languages.
The issue of Right-to-Left languages
Wikitext is plain-text code that is left-to-right, so writing articles in right-to-left language means mixing directions, and that’s a recipe for trouble. Symbols like pipe “|” colon “:” or parentheses “(” and “[” flip the sentence around when the sentence has mixed directions. You can read about some of those challenges in my blog post about that.
VisualEditor: The Solution
That’s where VisualEditor comes in. Instead of having to type articles using wikitext syntax, the idea is to have a visual interface that allows anyone to add content into articles easily, like a “WYSIWYG” system or a Word processor. This serves the purpose of making it easier for everyone to edit articles, even without knowing wikitext or being intimidated by weird symbols in the text editing area — and also help right-to-left language speakers to edit articles without bidirectionality frustration. And, also, it’s a lot more convenient to edit articles the way they are supposed to look than their source code.
Project Summary: Right-to-Left Language Support in Visual Editor
So, my project involves adding in language and right-to-left support, both in terms of fixing up bugs that prevented VisualEditor from being used on right-to-left Wikis, and also developing tools to help editors handle languages when editing wiki articles.
Language Inspector
The Language Inspector adds a “Language” button to the toolbar that allows users to mark certain text as a particular language. The code uses UniversalLanguageSelector to provide visual GUI for language selection and relate the language to its directionality.
A screenshot of a draft version of the VisualEditor language inspector. Credit: Amir Aharoni
TemplateData Generator
A MediaWiki extension that provides visual GUI for editing json-based <templatedata> tags.
TemplateData is a json string that is used by VisualEditor to recognize the elements and parameters of MediaWiki templates. Since templatedata is json string, it is not easy for users to manually edit it — especially so in right-to-left environment, where the mix of english-based json with rtl-parameters can make the editing process incredibly challenging.
TemplateData Generator allows users to use the GUI to either create the templatedata json string from scratch, by importing parameters, or to edit an existing one, without having to edit the text itself. The extension is also planned to be merged into an existing TemplateData extension that is deployed on the international Wikipedia.
TemplateData Generator with Hebrew parameters
Bug fixes
On top of those two projects, I’ve also spent some time fixing up right-to-left related bugs, some of which were blocking VisualEditor from being used in right-to-left wikis:
So that was the actual work, the “deliverables” that resulted from this great internship. But there were quite a lot of other beneficial results. Here’s a couple of things I’ve learned.
Programming Collaboratively
Since MediaWiki is a collaborative project, I learned a lot about how to write code with other people. Up until this project, my programming was mostly by myself. Sure, I’ve cooperated on code before, but it was mostly involving a tiny group of people, or it was me getting into someone else’s code and sending in a patch request. I knew about the idea that code can actually be worked on — and reviewed! — collaboratively, but it’s been completely different actually doing it.
I’ve learned that the industry relies on communication and cooperation to produce working programs, and while there are teams that do work on different aspects of these products, cooperation over making them work means there is “fresh eyes” going over the pieces, improving the system in general. Cooperating on code not only made the code I worked on be better, it made me be a better programmer.
Communication
I learned to communicate the problems I encounter and the solutions I come up with clearly. Sometimes, while thinking about how to explain the problem I got stuck with, I realized I might have a potential solution. Explaining to others clearly meant understanding things better for myself.
Since I speak Hebrew and my work involves Right-to-Left issues, I also tried to be in constant communication with the user base – especially the Hebrew Wikipedia – to hear about the bugs and problems that frustrate them. In that aspect, I had to learn how to translate the user complaint into a technical requirement and vise versa – when technical features came out, it was helpful to communicate them back to the users for their comments.
Programming Properly
I started this internship feeling rather insecure about my programming ability.
I’ve been programming various languages since I was rather young, but it was always more a hobby than an actual profession. I could make programs work, and for the most part, they work just fine, but this project involved getting into a really big, complex codebase and starting to make considerations that I’ve never had before. This project made me start considering not just working code solutions, but solutions that are efficient, that work with long-term product strategy, that work consistently, that survive millions of users and provide proper usability in wide variety of systems.
I wasn’t sure I can do that, but thanks to extremely talented and helpful team and mentors, and passionate users who pointed out the challenges they wanted fixed, I delved in, and I managed.
I think I did more than just managed, but the best thing of all of this, as far as I’m concerned, is that I’ve learned — a lot — about how to do things right. Really right. And I tell ya, I had a blast learning it.
Advice for future Google Summer of Code interns
If you’re going for a Google Summer of Code project, you know you’re going to work with Open Source companies, and if you really want to contribute and also get the most out of the internship, here is my two cents’ worth:
Don’t just Do it — Own it
If you want to really learn and get the best out of Google Summer of Code, you should own your project.
Find bugs that are related to the system you’re working on and fix them. Get in touch with the user base and encourage them to talk to you, be bold, ask questions, bug people on IRC and the mailing lists, try to see if there are parts of your projects that touch other related projects and go bug them, too.
Utilize the Community
I think that’s the best thing I’ve learned from this internship and the best advice I can give to future interns: Open source projects are a community.
You don’t just collaborate on code, you work together, plan together, and help one another.
Don’t be shy, don’t be mute, and don’t work in a bubble. Communicate, cooperate, discuss, do NOT let yourself be frustrated over problems for too long — the community is right there, waiting to be challenged with questions.
Do things right
Don’t just program – program with the open source code in mind. Document your code, learn the organization’s code style, ask for reviews and try to write code that other people can understand and tweak.
Don’t be intimidated. It’s worth it, really, because before you know it, people start sending others your way for answers on the things you’re working on.
And that’s the Best. Feeling. Ever.
So, yeah. It. Was. Awesome.
Thanks and Appreciation
So, as I sum up this incredible summer, I want to finish up with a thank-you list. This list is not complete, not even by a long shot; MediaWiki is a huge project with lots of volunteers, and many of them affected me and the progress of this project. But I will point out a few of the more notable groups of people who helped me this summer, and to which I am incredibly thankful.
You guys rock, y’all. You made this summer awesome, left to right and right to left!
So, Thank You to —
My mentors, Amir Aharoni and Inez Korczyński, for being incredibly accessible, supportive and helpful. Thanks, Amir, for encouraging me to take this project head-on despite my doubts about my abilities, for helping me see the big picture and what I need to look for, and, most of all, for making me feel like you’re actually enjoying the fact I constantly bug you. Thanks Inez for helping me get into a rather complex code and understand it enough to work with it, and for not letting me panic when I thought I broke things. Also, for not letting me break things too badly.
Timo Tijhof and Roan Kattouw from the VisualEditor team, for not only being experts, but allowing me to squeeze their expertise over and over again, and for being incredibly patient with my “wait wait wait, what?” baffled moments. Timo, thanks for showing me (by example and by code comments) what to look for and how to consider strategizing code, and for helping me strive to produce actually good code that others can use and work with. Roan, thank you for your endless patience (and yes, I mean e-n-d-l-e-s-s), for helping me get into the codebase, and for helping me climb out of the pits of panic when I managed to screw things up, and thank you both for making me feel like I kinda know what I’m doing, even when I didn’t.
James Forrester, VisualEditor product manager, for alleviating my worries and insecurities by being extremely welcoming, for making me feel like part of the team by assigning me bugs, by being there when I needed help (which was quite often, really,) by inviting me over to San Francisco to meet the team, and for offering me a job. That was awesome.
The VisualEditor superteam – Trevor Parscal, Ed Sanders, Rob Moen, and David Chan, who were there for my questions even when they didn’t realize it. Also, for an amazing San Francisco visit!
To the Wikimedia Language Team, and their hard work, for making me realize that speaking and writing RTL does not an RTL-programmer make, and for the absolutely rawkin’ UniversalLanguageSelector.
Sumana Harihareswara and Quim Gil without which I would not have submitted a proposal on time, or at all, for being totally welcoming for newbies like me, and for the great support throughout!
The Hebrew Wikipedia editors and system managers and users, for complaining and complementing and adding bugs to the list, so we can deal with them and make RTL support in VisualEditor awesomer and awesomer.
… And anyone and everyone who I interacted with this summer, from Parsoid to Vagrant to the various office hours and late-night-a-la-early-morning banter in IRC.
And to my parents, who brought me this far (this works better in Hebrew)
English is written left to right. Hebrew is written right to left. We know that. Browsers (for the most part) know that too, just like they know that the default directionality of a web page is left-to-right (LTR), and that if there is a setting that explicitly defines the direction to right-to-left, the page should flip like a mirror. Browsers are smart like that. Mostly.
But even browsers have problems when deciding what to do when languages are mixed up, and that, my friends, is a recipe for really weird issues when typing and viewing bidirectional text.
On The Bidirectionality of Characters and Strings
Before we delve into some interesting examples of mixed-up directionality problems, we should first go over how browsers consider directionality at all.
We already said that English is recognized as an “LTR” language (Left-to-Right), and Hebrew, Arabic, Urdu (and some others) as RTL languages (Right-to-Left). These are fairly clear, and if you type a string that consists of these languages on their own, the situation is more or less okay (but we’ll go over some issues with that later)
Hebrew and English (and a couple of others) are of the “strong” directionality types, the ones that not only have direction but also affect their surroundings. Some characters have “weak” directionality, where while they have directionality internally, they don’t affect characters around them. And some characters are merely neutral, whereas they get their directionality by their surroundings. Oh, and there are also some characters that may (and do) flip around visually depending on the text they’re in.
Don’t worry. I’m going to explain eeeeeeeeeeeeeeverything.
In the beginning days of the Internet, way way back, when Dinosaurs roamed the Earth and half of you who are reading this post were probably in diapers, the Internet assumed pretty much everything is left-to-right.
I remember building web pages in raw html that most of us would cringe at today. There were no “sites”, really, only a collection of static HTML pages which, more often than not, included horrendous tags like <blink> and <marquee> and featured pages where one-font-served-all and the backgrounds were tiled. Ah, the good ol’ days.
Those days, Hebrew was, in fact, typed backwards. If I wanted to write the Hebrew word “שלום”, which starts with the hebrew letter “ש”, I would have to type it backwards, starting with the letter “ם”, and produce “םולש” – because the letters would appear sequentially from left to right. This might be doable when typing one or two words, but if you had an entire paragraph or an entire article, it could get very annoying very fast.
There were several tools you could download in those ancient days that would take your text and flip it. ‘Cause that’s how we rolled back then.
Luckily, Unicode came in and defined directionality, and while it still has some problems, RTL users can at least type their language normally, rather than learn to write backwards. That helps.
Strong Types
Strong types are character sets that have explicit directionality. Hebrew is right-to-left, always. English is left-to-right, always.** When I type in either of those character-sets, my characters would appear in sequence, one after the other, according to the directionality. This is how the word “Hello” appears from left to right, while the word “שלום” appears from right to left.
Strong types also set the directionality of the space they’re in, meaning that if I inserted any characters that have weak or neutral directionality in the middle of the sentence you’re reading now (and I have already done that) they will assume the direction of the strongly typed string — in this case, English. So, strong type isn’t just about the character itself, but also its surroundings.
Weak types
Weak types are fun. These are sequences of characters that might have a direction, but it doesn’t affect their surroundings, and may be adjusted based on their surrounding text. In this group are characters like numbers, plus and minus signs, colon, comma, period and other control characters.
Neutral types are the funn’est. Neutral characters are character types that can be either right-to-left or left-to-right, so they completely depend on what string surrounds them. These include things like new-line characters, tabs and white-space.
Implicit Level Types: When what you type is not quite what you get
So we have strong types, weak types and neutral types, but that’s not where our directionality double-take ends. In fact, the real doozies are characters that are resolved differently (as in, they take literally different shapes) in either RTL or LTR.
Yes, you read that right, they actually literally and quite visibly look different when written inside an LTR string versus inside an RTL string.
The best examples for this are parentheses and (my personal best friend) the bracket. These symbols are, in fact, icons that represent direction already. The button on your keyboard that has “(” on it is not quite that, but rather a symbol of “open parentheses”. In English (which is left-to-right) the symbol is naturally ( to open parentheses, and ) to close them. But in Hebrew and Arabic and the other RTL languages, the “open parentheses” symbol is the reverse ), since the string is right to left. So this symbol would appear on your screen either ( or ) depending where you typed it.
I know, right?
Mishmashing Both Ways
In general, if one uses only one direction in a document (specifically online) the problems are not as noticeable, because the strongly typed text surrounds all other weak and implicit-level character types, making them its own type by default.
The issues come up when we have to mix languages and directions, or use RTL language inside a block that is meant for LTR. This happens a lot online — if there is no explicit dir=”rtl” anywhere in the HTML document, the document defaults to LTR directionality. The directionality of the page (either by using dir=’rtl’ or dir=’ltr’ or not using dir= attribute at all and relying on it’s default fallback to ‘LTR’) is considered to explicitly set the directionality of the expected text. So, any characters of ambiguous directionality will take on the direction that was set by that attribute.
If, say, I try to type an RTL language inside a textbox in a page that has dir=’ltr’, I can run into a lot of annoying problems with punctuation, the positions of segments of the sentence, and mixing languages of a strong type. The same happens the other way around, if I try to type an LTR language (Say, English) inside an RTL-set textbox.
It can get so confusing, that, quite often, as I try to figure out how to type LTR text into an RTL box and see how my text actually organizes itself, my state of mind is pretty much this:
The Good, The Bad, and The Ugly
So, obviously, the creation of Unicode was much superior to the reverse-typing (and the need to use multiple individual fonts) that existed before it. Browsers tend to follow the Unicode rules (though some apps that do their own rendering sometimes don’t, but that’s a different issue.) And this Unicode directionality algorithm gives us a lot of really Good Things to work with when typing different directions, but it also has so Bad Things, and occasionally, even some really Ugly Things.
The Good Things
There are, indeed, a bunch of good things that happen due to Unicode’s bidirectionality algortithm. As I’ve already mentioned, the fact RTL users can type their language normally (and not backwards) is already a good thing (and I know, I used the system when it didn’t have that nice feature.)
Some other benefits of the bidirectionality algorithm is the fact we can use numbers (which are weakly typed LTR) inside RTL text. So, for instance, consider this text:
ניפגש ב09:35 בחוף הים
Literally, this means “we will meet at 09:35 at the beach”. Notice, though, that even without any directionality fixes the numbers 09 and 35 are left-to-right as they should be, because that’s how numbers are read — but I didn’t really need to manually reverse my typing when I wrote this sentence — the browser did it for me.
Here’s a nice exercise though: select that sentence. When you do, you can see exactly what piece has what directionality.
Which leads me to–
The Bad Things
Selections
Selections are a major part of the problem of bidirectional text. As you can see from the example of the “good thing” (that I don’t need to reverse typing) there is also a bad side, which is how to select my text. Selection can be LOGICAL or VISUAL. This is also true to cursor movement, which we will go over in a second.
Visual selection is simply that — visual — which means that the selection treats the segment of text as if it’s one continuous block, regardless of directions.
Logical selection means the text is divided to its bidirectional pieces. That means that if I start my selection at the beginning of an RTL text (at the right) and drag my mouse towards its end (to the left) the selection will split when I reach the number part, because the numbers are left-to-right.
This is, indeed, logical, because it goes from logical “start” to logical “end”, and since the text is bidirectional, those two pointers are different for each of the sections. It makes a lot of sense, but it can be confusing.
Cursor Movement
Similarly, the cursor can also move either logically or visually. This can be a little confusing, and sometimes this behavior is inconsistent across platforms. Most of the time, though, the movement is logical.
So, here’s a quick test of where this behavior can become really weird. Consider the following sentence. It is inside a textbox so you can select it and move your cursor within it properly.
Try to select the text from the start (left) to the end (right). See what happens when you hover over the Hebrew words?
Now, if you move your marker inside the given textbox, the cursor (in Chrome and Firefox in Windows, at least) will move VISUALLY and not logically. That is, you can just move from end to start as if there are no two different languages there.
But try to copy/paste this string into Notepad (or equivalent simple software) and move the cursor from start to end. Usually, those editors would move the mouse LOGICALLY. Which, to be fair, makes more sense than visual movement.
It also shows you how RTL behavior can be somewhat unpredictable; some programs do it this way, some that way. Some browsers will go visual, some logical, and there are some CSS rules that can override those decisions, too, so it may change on a website to website basis.
Nice, eh?
Punctuation Marks
Well, that was a textbox that was “LTR” to begin with. What happens, though, if I write a Hebrew sentence in an LTR box, or the other way around – an English sentence in an RTL textbox? That’s when our lovely friends — the weakly typed punctuation marks – come out to play.
Whoops, where’s the final period?
Here’s the reverse version:
Where’d that final period go?
Two languages together, Koombaya
Here’s something even better, though, that relates to both selections and cursor movement (and rendering, and usage, and and — anyways).
The above examples featured some strong type (English or Hebrew) that is mixed with some weak typed (numbers) and is mixed up by the neutral type (white space). But what if I create a string that has two opposite strong types mixed with neutral type white-spaces and weak type punctuation?
Go ahead, try to select that sentence from beginning to end:
Let’s go over what goes on in that horrific textbox for a minute. First of all, part of the problem in the first textbox is that the textbox was forced RTL, and since most of the text in it was English, it broke in weird places. Here’s the sentence when it is forced to be LTR:
Remember that English is strongly typed for LTR but עברית is strongly typed for RTL. When mixing English ועברית together you may get some surprising results.
Notice, though, that the textbox problem also happened just the same in the reverse case, where the box was LTR and the sentence was mostly RTL.
With a forced-RTL textbox (and majority of text strongly typed for LTR) the spaces took the directionality of the text they were surrounded by – which is LTR. Then we had a strongly-typed RTL word in Hebrew, which made the space inside it turn RTL, but the surrounding white space (the one between the RTL word and LTR sentence) was still affected by the surrounding text – which is LTR.
If you’re still with me here, this may help drive the point home. Essentially, you had this:
The entire sentence structure was right-to-left, but the small English segment was left-to-right.
Overall “chunk” direction was RTL. Each chunk had its own internal direction. When you read it, it looks all jumbled — because it is.
And that happened exactly the same (only in reverse) in the second textbox. With LTR instead of RTL, and vice versa.
I know. I… know.
The Ugly Things
Now we move to the ugly area, the things that are not just difficult behavior, but are also producing visually different results. Remember those weak typed and implicit-level types? That’s where these come in, and they, I tell you, they have a blast confusing us thoroughly.
White Spaces
White spaces are implicit-level types, which means they are defined by the text they live in. The spaces in the sentence you’re reading right now are implicitly LTR, since they are inside an English text. The white spaces here:
במשפט הזה יש רווחים ואלה מוגדרים ימין לשמאל
Are implicitly RTL because they’re inside hebrew, even though the page itself is LTR.
This is good, but it also produces some weird results. Consider the situation where I have a set of numbers inside a text. The numbers are separated by whitespace — and the whitespace is defined by the surrounding text. But numbers themselves are “weak” typed — which means they do not affect their own surroundings (even though they are internally LTR) The whitespaces would have to take their directionality from whatever words surround the entire segment of numbers.
This sounds weird? The behavior is even weirder. See this, for instance:
I purposefully encapsulated those numbers in an RTL text, and so the whitespaces that separate these are still LTR. What do you think would happen, though, if I replace those english words with Hebrew (RTL) ones?
Well, this example is exactly the same sentence and sequence of numbers, in the same exact order, with the single difference that “Start” and “End” were replaced by their prospective Hebrew words.
The numbers are reversed! The numbers… are… Head spinning yet?
This might be weird, but it makes sense; the spaces are now encapsulated in an RTL text which means they are now RTL. The space in rtl sentences is right-to-left, so the grouping of numbers go from the right and to the left.
But I think your head isn’t spinning fast enough just yet. What would happen if we added spaces inside the number grouping itself? I mean, the numbers are internally LTR, but the space is RTL, so we will add a space to break the group and.. and the group will go… spinning?
Try it. Add a spaces to the number groups below.
See it? SEEEEEEEEEE it?
Yeah. Exactly.
Parentheses and Brackets
As we discussed earlier in this post, brackets and parentheses are, in fact, representing “start-of” and “end-of” which means that depending where they are inserted, they may appear on different directions on your screen.
So, if I press the button that has a nice little “[” on it on my keyboard (below the { and near the P) I will get different results in LTR and RTL.
Yes, I clicked the same button. Yes, I’m sure. You’re welcome to go over the source.
More than being a weird thing, this effect makes it incredibly frustrating when, inside an RTL textbox, there’s a need to add some html <tags>. And, yes, this happens in Wikipedia, and in the RTL Wikipedias too.
Try adding a <span style=”font-size: 2em”> to some segment of the text below. Good luck, stay sane, and remember to breathe. If you feel especially adventurous, you could also try to insert some wikitext, like a link to a page “Somewhere” (english link) with a hebrew caption.
Want to go even wilder? Add some English text after the Hebrew one, and try to set some <a href=”something.html”> </a> starting from the Hebrew string, and ending at the English one.
Type it all, don’t cheat and copy/paste. Try it for realz. Go ahead, play. Experiment. Go RTL crazy.
So how is this relevant to VisualEditor?
As a text editor, VisualEditor expects users to type into it, and that they do. They also do that in multiple languages, and, more often than not, in mixed languages inside the same article. Mixing languages is extremely common, especially in Wikipedia, when there’s a need to provide the original script of a word taken from another language, or a city name in its native script, etc.
But as we saw, typing can be tricky, especially when we mix directions. We have to make sure we allow the users to type while seeing the result they will get in the page logically. We also have to make sure that their typing makes sense, and that if there is a need to describe a specific span of text as a different direction, they can do that easily. We have to make sure their input is interpreted correctly, that RTL appears properly in the ContentEditable screen, and then renders properly in the article that is saved.
Also, as you can see from my above example with the [ character — there’s a difference between the HTML code and the resulting rendering. That is, I typed [ but got ] and [ appeared in the code, but ] appeared in my resulting rendered markup. Which should happen inside VisualEditor? WYSIWYG is quite a lot more different when what you type is expected to be flipped.
These things aren’t impossible to deal with, but they are quite challenging and they often require decision-making about what a user should expect. Most applications online (and offline) have problems dealing with LTR/RTL typing, making these strategic decisions even more complicated. The behavior needs to be designed according to what we think is the best way to do it, and not what the RTL users expect — because as you can see from the current behavior, RTL users usually expect horrendous behavior.
It’s the good kind of challenge, though. The kind a lot of people care about finding a good way to fix.
But wait, There’s more
There’s a bunch of other issues with bidirectional text, some of which are problems that exist in published software and apps online and make RTL’er’s lives rather annoying. I may write about that at some point, and share my RTL frustration.
In this article we went over issues with RTL strings inside LTR boxes, problems with characters of ambiguous directionality, with selections and cursor movements and general “huh”isms. There are, of course, more RTL hardships, but this post was meant to serve as a sort of introduction to the main and most common bidirectionality issues.
I hope you’ve enjoyed it. At least, I hope you now understand what the programmers (and RTL users!) need to deal with. I tried to make it easier on you with some animated gifs. You’re welcome.
And so, until next time: !oo-eldoot
Remark Regarding Languages and Scripts
In this article, I use the term “Language” to refer to English and Hebrew letters. In fact, I should be using the term “Script”, to refer to the letters and characters themselves. The difference comes mostly from the fact that while Hebrew and English are languages, they each use characters that may be used in other Languages. For instance, English uses latin script, and Hebrew script can be used in Yiddish language as well.
So, take into account that this is the case, and that the actual letters that are used and are LTR or RTL are really “script” and not quite the language — since the browser doesn’t really care what words you literally type using these scripts.
For the sake of simplicity and to try and reduce some of the confusion, however, I made a tactical decision to group it all up to the most familiar terminology of “Language”.
(Thanks MatmaRex for pointing out I should at least mention this difference)
I sit in front of my trusty computer, coding-away right-to-left popup-location fixes in anticipation of the new VisualEditor deployment in the Hebrew Wikipedia. The hard part, I tell myself (and with good reason) is calculating the mirroring coordinates; which object to I use as parent to mirror my coordinates against?
As I’ve explained in a previous post, the positioning and mirroring of nested elements can be a real challenge — the RTL/LTR Vertigo.
This time, the element whose position I was trying to mirror popped up inside another widget — a frame inside a frame — which made positioning all that much trickier, since it’s all relative to one another. In cases like these, I find myself following up on the relative positioning of several elements in the nesting chain; even Einstein’s head would’ve spun.
The principle, however, is the same — flip the ‘left’ position with the mirrored ‘right’ position, relative to the parent container.
Similarly to last time, the fixed code looked like this:
// ('dimensions' variable was set above according to ltr positions)
// Fix for RTL
if ( this.$.css( 'direction' ) === 'rtl' ) {
dimensions.right = parseFloat( this.$.parent().css( 'left' ) ) - dimensions.width - dimensions.left;
// Erase the value for 'left':
delete dimensions.left;
}
this.$.css( dimensions );
In VisualEditor, this.$ represents the jQuery object of the object we’re in (‘this’). Since I am calling for a jQuery function ‘css()’, I must refer to the jQuery object, rather than the VisualEditor object.
I can test the RTL direction property this.$.css( ‘direction’ ) on my popup widget because the direction is an inherited property; even if I didn’t set “direction:rtl” explicitly, the element will inherit it from the parent, who will inherit it from its parent.. etc etc forever and ever. Well, at least until an element with defined directionality is found, and if none is found, then, as far as it should go, the default is LTR.
So this should have worked. And in Firefox, it did. But not in Chrome.
Firefox and Chrome
The coordinate mirroring worked beautifully in Firefox.
It also failed beautifully in Chrome. But it’s all about math, isn’t it? Parent position minus some left value, minus some width minus– math is math. Is math. So why, I begged my screen. “Whyyyy aren’t you working??”
The Real Problem
The problem with Chrome wasn’t the cause, it was a symptom. The real problem was the way I read through the positioning of the elements. In specific, the problem was this line:
this.$.parent().css( 'left' )
This line reads the parent object’s css “left” property, which was defined (I checked!) so it should have worked. In theory, I should have gotten the ‘left’ position of the parent. Right?
Sure. I did get the left property — but that’s exactly the problem. What I got was the CSS property of the element, I didn’t really get the actual coordinates the element was positioned. Not quite, not exactly, and not entirely.
css(‘left’) vs position().left vs offset().left
There are several ways to read the position of an element, and each one of those gives you a slightly different value. They’re all true, it just depends what, exactly, you mean to use.
css( ‘left’ ) returns the calculated value of the CSS property. It is the “left:10px” that exists either in the css stylesheet or in the style=” property of the element.
position().left returns the position of the element relative to the offset parent.
offset().left returns the position of the element relative to the document.
Differences in Browsers and Screens
There may be subtle differences in the way browsers render result differently, the value of the css(‘left’) property can be different across browsers. position() and offset() are actual x/y values, so requesting these values will give me the actual position of the element (in whatever browser it was rendered) rather than the ‘requested’ value the CSS style contains.
Since the positions are relative to one another, it won’t do me much good to have the position in relation to the document. What i really need is the x/y positions of my parent element in relation to its own offset element. That is, I need position() value.
Notice one more thing: css(‘left’) will return the css value – a number and units – like ‘100px’, which is why I needed to encapsulate it with “parseFloat” before I continued with the calculations. On top of that, I run the risk of the css style returning ‘auto’ which would be parsed into 0 and render the entire mirroring action completely faulty.
position() and offset(), however, return x/y values, which are numerical, and represent the actual distances and positions relative to their parent and the screen.
VisualEditor Supercalifragilisti-Nested Divs
VisualEditor has lots of nested divs. And nested iFrames inside divs, that also have divs in them. And many of those get some position property along the chain; a Widget may get to be positioned at the center of the screen, while its panels are positioned with some percentage according to their size, and they, in turn, will have an input that has a popup attached.
And they’re all relative, and most of them has their positions injected dynamically, since the position most of the time depends on either where your marker is, or where your mouse is, or where whatever element you intend to edit is located, etc etc.
All of this makes flipping coordinates in VisualEditor challenging.
But the bigger challenge comes when we do that while calculating the offset and/or position() value of another element. We actually do that quite a lot, especially with popup widgets. For instance, inside the Page Settings window, you can add new Categories. Typing the category name in the input pops a “suggestion menu” that appears right under it. That means that for the suggestion menu to appear correctly, we need to check where the input element (which is it’s “sibling” in the nesting chain) is located, and mirror the coordinates. But we need to be careful and check that we don’t mirror mirror coordinates (because that won’t make sense) or mirror already mirrored mirror mirror coordina— well, you get my drift. It can be confusing.
On top of that, VisualEditor popups are iframes, and iframes are problematic with jQuery as it is, especially when they pop up already inside other iframes (re category popup inside the Page Settings widget).
The more we depend on other dynamically positioned elements, the more we run the risk of having inconsistencies when mirroring those coordinates.
Since my popup widget appeared inside another widget, the offset and general different in rendering was probably more emphasized than if the element appeared as part of the main VisualEditor surface. So, the solution was rather simple:
// ('dimensions' variable was set above according to ltr positions)
// Fix for RTL
if ( this.$.css( 'direction' ) === 'rtl' ) {
dimensions.right = this.$.parent().position().left - dimensions.width - dimensions.left;
// Erase the value for 'left':
delete dimensions.left;
}
this.$.css( dimensions );
And that worked like a charm.
Many thanks go to Timo Tijhof (Krinkle) who found this problem by spotting it in Chrome, and to Roan Kattouw (Catrope) for figuring out the solution is to use position().left
I’m excited to announce the first release of a product I’ve been working on for the last several months: the Miga Data Viewer. Miga (pronounced MEE-ga) is an open source application, mostly written in Javascript, that creates an automatic display interface around a set of structured data, where the data is contained in one or more CSV files. (CSV, which stands for “comma-separated values”, is a popular and extremely lightweight file format for storing structured data.) You supply the file(s), and a schema file that explains the type of each field contained in that file or files, and Miga does all the rest.
“Miga” means “crumb” in Spanish, and informally it can mean (I think) anything small and genial. The name helps to suggest the software’s lightweight aspect, though I confess that mostly I just picked the name because I liked the sound of it. (There’s also a resemblance to the name “MediaWiki”, but that is – I think – a coincidence.) As for the “data viewer” part, I could have called it a “data browser” instead of “data viewer” – in some ways, “browser” more accurately reflects what the software does – but that would have had the initials “DB”, which is already strongly associated with “database”. I also considered calling it a “data navigator” or “data explorer” instead, but I liked the compactness of “viewer”.
Conceptually, Miga is based almost entirely on the Semantic MediaWiki system, and on experiences gained working with it about how best to structure data. Miga began its life when I started thinking about what it would take to create a mobile interface for SMW data. It wasn’t long into that process when I realized that, if you’re making a separate set of software just for mobile display, that same set of software could in theory handle data from any system at all. That’s what led me to the “data is data” theory, which I wrote about here earlier this year. To summarize, it’s the idea that the best ways to browse and display a set of data can be determined by looking at the size and schema of the data, not by anything connected to its subject matter. And now Miga exists as, hopefully, a proof concept of the entire theory.
The practical implementation of Miga owes a lot to Semantic MediaWiki as well. The structure of the database, and the approach to data typing, are very similar to that of Semantic MediaWiki (though the set of data types is not identical – Miga has some types that SMW lacks, like “Start time” and “End time”, that make automatic handling easier). The handling of n-ary/compound data is based on how things are done in SMW – though in SMW the entities used to store such data are called either “subobjects” or “internal objects”, while in Miga they’re called part of “unnamed categories”. And the main interface is based in large part on that of the Semantic Drilldown extension.
You can think of Miga as Semantic MediaWiki without the wiki – the data entry is all required to have been done ahead of time, and the creation of logical browsing structures is done automatically by the software.
There’s another way in which Miga differs from SMW, though, which is that the data is stored on the browser itself, using Web SQL Database (a feature of browsers that really just means that you can store databases on the user’s own computer). The data gets stored in the browser when the site is first loaded, and from then on it’s just there, including if the user closes the browser and then navigates to the page again. It makes a huge difference to have the data all be stored client-side, instead of server-side: pages load up noticeably faster, and, especially on mobile devices, the lack of requirement of the network after the initial load has a big impact on both battery usage and offline usability – if you load the data in the browser on your cell phone, then head into an area with no coverage, you can keep browsing.
The website has more information on usage of the software; I would recommend looking at the Demos page to see the actual look-and-feel, across a variety of different data sets. I’ll include here just one screenshot
Hopefully this one image encapsulates what Miga DV can do. The software sees that this table of data (which comes from infobox text within the Wikipedia pages about public parks) contains geographical coordinates, so it automatically makes a mapping display available, and handles everything related to the display of the map. You can see above the map that there’s additional filtering available, and above that that one filter has already been selected. (And you can see here this exact page in action, if you want to try playing around with all the functionality.)
Miga DV is not the only framework for browsing through arbitrary structured data. Spreadsheets offer it to some extent, via “pivoting” and the like, including online spreadsheet applications like Google Docs. The application Recline.js offers something even closer, with the ability to do mapping, charting and the like, although the standard view is much closer to a spreadsheet than Miga’s is. There are libraries like Exhibit and Freebase Parallax that allow for browsing and visualization of data that’s overall more sophisticated than what Miga offers. Still, I think Miga offers an interface that’s the closest to the type of interface that people have become used to on the web and in apps, with a separate page for each entity. That, combined with the ease of setup for administrators, makes Miga a good choice in many situations, in my opinion.
There’s also the element that Miga is open-source software. I know less about what’s going among proprietary software in this field, but I wouldn’t be surprised if there’s similar software and/or services that costs money to use. There’s certainly no shortage of proprietary app-development software; the advantage of an open-source solution over paid software is a matter of personal opinion.
What next? There are a few features that I’m hoping to add soon-ish, the most important being internationalization (right now all the text displayed is hardcoded in English). In the longer term, my biggest goal for the software is the ability to create true mobile apps with it. There are a few important advantages that mobile apps have over web-based applications; the biggest, in my opinion, is they can be used fully offline, meaning even if the phone or device is shut off and then restarted somewhere with little or no reception. People do also like the convenience of having a separate icon for each app, though that can be replicated to some extent with URLs (which, as I understand, is easier to do on iOS than Android.)
My hope is of course that people start to make use of this software for their own data – both for public websites and for private installations, such as within corporations. Maybe Miga, or systems like it, will mean that a lot of data that otherwise would never be published, because creating an interface around it would take too much money and/or developer time, will finally get its day. And beyond that, it would be great if some sort of user and developer community grew around the software; but we’ll see.
The Issues of Coordinate Systems (or: Mirroring XY, Oh My!)
Published 21 Jun 2013
by Moriel Schottlender
on MediaWiki.
I’ve spent a lot of my Physics education dealing with calculations. Calculating positions of objects as they move in space, particles in some electric field, planets around a certain star, and more, more and some more. In Physics, Mathematics is the language we use to represent reality, perform predictions, and validate them.
So it was only natural that when I deal with flips and mirroring when it comes to Right-to-Left vs. Left-to-Right support, I expected to handle these with ease. After all, after transforming relative frames and different types of physical field coordinates to one another, what’s transforming cartesian to mirror-cartesian?
Well, apparently it’s something.
Computer Coordinate System
Computer software, and especially web-based content, is originally meant to be read in English; left to right, top to bottom. When an application loads on any screen, it isn’t necessarily clear what the size of the visible content would be, especially with the advent of mobile devices of all shapes and sizes.
It makes sense, then, to start your coordinate system origin at the top-left corner, where the page begins to load, and go onwards from there — to the right, and to the bottom. So, going right on the axis increases X, and going down from the axis increases Y.
It makes perfect sense for computers to behave this way. Really. I get it. So.. what’s the problem, you ask?
The Problem
Eh. This difference between +y and -y makes using real-life calculation inside computer applications all that much more complicated. Whenever we deal with mathematics in physics and in the real world, we take our coordinate system as starting from the bottom-left corner. That means that going right on the origin increases the value of X, and going up from the origin increases the value of Y.
That’s exactly a horizontal mirror of what Computers expect.
This can be handled by flipping the value of y, of course ,but it is still the source of many a-frustrations, especially when programming applications that invlove physical formulas, the more elaborate the more complicated to keep track of. Also, this makes multiplications and additions — and the calculation of vector combinations – rather annoying.
But the issue becomes even more elaborate when we deal with complex positioning of elements that are nested in one another or are dynamically positioned. Not only do we need to deal with a flipped y, we also need to deal with dynamic calculations involving relative positioning.
Practical vs Conceptual
This problem of the flipped y axis is more an annoyance than an actual practical issue. Even if we deal with position calculations purely mathematically, there are ways to convert the Real World coordinates into computer-driven coordinates with some (quite basic) transformation function that mirrors the y’ values.
The main problem, though, is conceptual.
For example, when I work on improving RTL support in the new Visual Editor in MediaWiki, part of the issues I deal with are the locations of popups. The locations for these popups are often calculated dynamically, depending on where your marker is located.
You would think that this won’t cause any problem to an RTL content. After all, the x=10 position is still x=10 even in an RTL language. Whatever positions are calculated should remain in place even if the directionality of the page changed.
Not quite.
Relative Positioning
HTML elements are often relatively placed, especially when they’re nested inside other elements. For example, consider this HTML snippet:
The ‘child’ div is nested inside its ‘master’ div. The master is pushed all the way to the left, since it has “left=0” style value. The child has ‘left=150’, which would mean that the actual position of the child (assuming no other margins or any other parent positioning) is 150px from the left edge.
Now the parent div is pushed all the way to the right of the screen, because of its “right:0” style. But the child div is still placed 150px from the left — this time, however, since it’s placed 150px to the left of its parent, it would be aaaaaaaaaaaall the way to the right +150px – essentially outside the screen.
Of course ,you can correct some of those problems with relative positioning, but relative positioning isn’t always what you need or want. And in the case of VisualEditor, many of the elements are surrounded by multiple other <div> elements that have their own calculated position values relative to the marker and the rest of the text. That’s on purpose, and it shoud stay this way.
Directionality Switching
So, why is the above example so important? Here’s why: When you switch content between LTR to RTL, you switch the directionality of the page. The ‘left’ style in the ‘master’ div above often has to be changed to ‘right’ so logical positions of text and buttons work out. Or, if you use something like CSSJanus, it may change automatically.
Example Bug: Visual Editor Link Popup in RTL
One of the bugs that I am trying to tackle in VisualEditor right now is the problem of the missing popup link in RTL wikis. If you edit an article and insert a link in LTR wiki (like English) a little popup will materialize, allowing you to change the target of the link and choose whether it is external or Wiki-Internal. Very cool and very useful.
In RTL, however, that link doesn’t pop up. It was fairly clear from the get-go that this is a CSS issue, some positioning problem that occurs when the page is “flipped” right-to-left instead of left-to-right — and, indeed, that is the case. While the parent’s position (defined in a CSS class) was flipped to be “right:0” in RTL, the popup itself still had a dynamically calculated “left” value. This conflict essentially put the entire popup at the outside of the screen.
The solution involved a simple change of popup direction style to the right, and recalculation of the distance from the new origin (right instead of left). Recalculating right to left when the marker is concerned is relatively easy. It looks something like this:
That solved the issue of the main popup, but it didn’t solve the issue of the subpopup. In VisualEditor, the link inspector is comprised of two popups: The main one involving the input in which you can enter your target page (inside the wiki or external http url) and a sub-popup that includes a list of suggestions.
Both popups have dynamically calculated values to the “left” in the LTR version. Both were changed to the ‘right’ with the above pseudocode. But what fixed the main popup, didn’t fix the sub-popup.
The sub popup appeared skewed, almost at the right place but not entirely, mocking me with its imperfect positioning.
Link popup and its suggestions sub-popup after RTL fix. It appears — but not quite right
The Solution
It took me a while (and some gentle coaxing from my mentors) to realize what was happening, and when I did, it seemed rather obvious.
The main popup calculates its position in relation to the marker, and the sub-popup calculates its position in relation to the first popup — both popups are inside a parent div that is, also, dynamically placed.
The mirroring should not be calculated in relation to the entire screen, because the positions (left or right) are set in relation to whatever container div holds the popups and not in relation to the entire screen.
The only reason I didn’t notice this fact with the main popup is that its skew’yness wasn’t all that evident, it appeared a little to the right but still inside the selected word. But when the second popup is misaligned, it’s noticeable.
The mirroring should be done in relation to whatever container holds the popup, and not assume that the position is mirrored across the entire screen.
Regardless of the actual solution, this problem raised an important issue: LTR to RTL switches can involve some dynamic calculations that may be somewhat messy, and when we switch the directionality of an entire page, some elements in it may flip (those who have CSS classes, mostly) and some may not (those who have dynamically calculated positions that are injected inline).
That means that examining the code and trying to calculate the transformation of the mirroring can be a truly confusing experience, one that I hereby name “The LTR/RTL Vertigo“.
Some elements flip, some don’t, some values require change, some don’t, some are relative to their parents and some relative to a grand-parent or the content box itself. And then, of course, there’s the fact that the x/y axis are the mirror of what I am used to from my Physics background. Did I say Vertigo already?
But don’t worry, this condition is mostly harmless, mostly temporary, and is mostly solved with a quick break from the screen and exposure to the summer sun to remind oneself that there is, in fact, a world out there.
So, until next time – Beware the RTL/LTR Vertigo, think of relative positioning, calculate your math mirrored, and go outside a little. It’s actually kinda nice.
This year I had the distinct privilege of being accepted to the Google Summer of Code summer internship, working for the Wikimedia Foundation. I will be responsible for improving Right-to-Left support in the new Visual Editor.
It’s really fun work, though quite challenging, and the fact my fixes (when and if they pass review) are implemented in the system and are used by Wikipedians all over the world, is quite satisfying.
My new motto for 2013 is: “data is data”. What does that mean (aside from being a tautology)? It means that data has a set of behaviors and a “personality” all it own, very much distinct from its underlying subject matter, or from what format it’s in. Ultimately, the fact that a table of data holds an ID field, three string fields and a date, and that it has 300 rows, says more about how to display and interface with it than the fact that it’s an elementary school activity listing, or a description of video game characters, or top-secret military information, or the results of biotech research. And the fact that the data is in an Excel spreadsheet, or a database, or embedded as RDF in a web page, shouldn’t matter either.
What is data?
I should first define what I mean by data. I’m talking about anything that is stored as fields – slots where the meaning of some value can be determined by the name or location of that value. And it should be information that represents something about the outside world.
For that latter reason, I don’t think that information related to communication – whether it’s email, blog posts, microblogs and status updates, discussion forums and so on – is truly data, though it’s usually stored in databases. It’s not intended to represent anything beyond itself – there’s data about it (who wrote it and when, etc.), but the communication itself is not really data. Tied in with that, there’s rarely a desire to display such communications in a venue other than where it was originally created. (Communication represents the vast majority of information in social networking sites, but it’s not the only information – there’s also real data, like users’ friends, interests, biographical information and so on.)
Data can be stored in a lot of different ways. I put together a table of the different terms used in different data-storage approaches:
Database/spreadsheet
Table
Row
Column
Value, cell
Standard website
Category, page type
Page (usually)
Field
Value
Semantic MediaWiki
Category
Page (usually)
Property, field, template parameter
Value
Semantic Web
Class
Subject
Predicate, relationship
Object
Object-oriented programming
Class
Object, instance
Field, property
Value
What’s the most obvious observation here (other than maybe the fact that this too is a table of data)? That, for all of their differences, all of these storage mechanisms are dealing with the same things – they just have different ways to refer to them.
A wrapper around a database
The vast majority of websites that have ever been created have been, at heart, code around a database, where the code is mostly intended to display and modify the contents of that database. That’s true of websites from Facebook to eBay to Craigslist to Wikipedia. There’s often an email component as well, and sometimes a credit card handling component, and often peripherals like ads, but the basic concept is: there’s a database somewhere, and users can use the site to navigate around some or all of its contents, some or all users can also use the site to add or modify contents. The data structure is fixed (though of course it changes, usually getting more complex, over time), and often, all the code to run the site had to be created more or less from scratch.
Of course, not all web products are standalone websites: there’s software to let you create your own blogs, wikis, e-commerce sites, social networking sites, and so on. This software is more generic than standalone websites, but it, too, is tied to a very specific data structure.
So you have millions of hours, or possibly even billions, that have been spent creating interfaces around databases. And in a lot of those projects, the same sort of logic has been implemented over and over again, in dozens of different programming languages and hundreds of different coding styles. This is not to say that all of that work has been wasted: there has been a tremendous amount of innovation, hard work and genius that has gone into all of it, optimizing speed, user interface, interoperability and all of that. But there has also been a lot of duplicated work.
Now, as I noted before, not all data stored in a database should be considered data: blog posts, messages and the like should not, in my opinion. So my point about duplicated work in data-handling may not full apply to blogs, social networking sites and so on. I’m sure there’s needlessly duplicated work on that side of things as well, but it’s not relevant to this essay. (Though social-networking sites like Facebook do include true structured data as well, about users’ friends, interests, biographical information, etc.)
What about [insert software library here]?
Creating a site, or web software, “from scratch” can mean different things. There are software libraries that work with a database schema, making use of the set of tables and their fields to let you create code around a database without having to do all the drudgework of creating a class from scratch from every table, etc. Ruby on Rails is the most well-known example, but there’s a wide variety of libraries in various languages that do this sort of thing: they are libraries that implement what’s known as the active record pattern. These “active record” libraries are quite helpful when you’re a programmer creating a site (I myself have created a number of websites with Ruby on Rails), but still, these are tools for programmers. A programmer still has to write code to do anything but the most basic display and editing of information.
So here’s a crazy thought: why does someone need to write any code at all, to just display the contents of a database in a user-friendly manner? Can’t there be software that takes a common-sense approach to data, displaying things in a way that makes sense for the current set of data?
No database? No problem
And, for that matter, why does the underlying data have to be in a database, as nearly all web software currently expects it to be? Why can’t code that interfaces with a database work just as well with data that’s in a spreadsheet, or an XML file, or available through an API from some other website? After all, data is data – once the data exists, you should be able to display it, and modify it if you have the appropriate permissions, no matter what format it’s in.
It’s too slow to query tens of thousands of rows of data if they’re in a spreadsheet? Fine – so have the application generate its own database tables to store all that data, and it can then query on that. There’s nothing that’s really technically challenging about doing that, even if the amount of data stretches to the hundreds of thousands of rows. And if the data or data structure is going to change in the outside spreadsheet/XML/etc., you can set up a process to have the application keep re-importing the current contents into its internal database and delete the old stuff, say once a day or once a week.
Conversely, if you’re sure that the underlying data isn’t being modified, you could have the application also allow users to modify its data, and then propagate the changes back to the underlying source, if it has permissions to do so.
Figuring out the data structure, and other complications
Now, you may argue that it’s not really possible to take, say, a set of Excel spreadsheets and construct an interface out of it. There’s a lot we don’t know: if there are two different tables that contain a column called “ID”, and each one has a row with the value “1234″ for that column, do those rows refer to the the same thing? And if there’s a column that mostly contains numbers, except for a few rows where it contains a string of letters, should that be treated as a number field, or as a string? And so on.
These are valid points – and someone who wants to use a generic tool to display a set of data will probably first have to specify some things about the data structure: which fields/columns correspond to which other fields/columns, what the data type is for each field, which fields represent a unique ID, and so on. (Though some of that information may be specified already, if the source is a database.) The administrator could potentially specially all of that “meta-data” in a settings file, or via a web interface, or some such. It’s some amount of work, yes – but it’s fairly trivial, certainly compared to programming.
Another complication is read-access. Many sites contain information that only a small percentage of its users can access. And corporate sites of course can contain a lot of sensitive information, readable only to a small group of managers. Can all of that read-access control really be handled by a generic application?
Yes and no. If the site has some truly strange or even just detailed rules on who can view what information, then there’s probably no easy way to have a generic application mimic all of them. But if the rules are basic – like that a certain set of users cannot view the contents of certain columns, or cannot view an entire table, or cannot view the rows in a table that match certain criteria, then it seems like that, too, could be handled via some basic settings.
Some best practices
Now, let’s look at some possible “best practices” for displaying data. Here are some fairly basic ones:
If a table of data contains a field storing geographical coordinates (or two fields – one for latitude and one for longitude), chances are good that you’ll want to display some or all of those coordinates in a map.
If a table of data contains a date field, there’s a reasonable chance that you’ll want to display those rows in a calendar.
For any table of data holding public information, there’s a good chance that you’ll want to provide users with a faceted search interface (where there’s a text input for each field), or a faceted browsing/drill-down interface (where there are clickable/selectable values for each field), or both, or some combination of the two.
If we can make all of these assumptions, surely the software can too, and provide a default display for all of this kind of information. Perhaps having a map should be the default behavior, that happens unless you specify otherwise?
But there’s more that an application can assume than just the need for certain kinds of visualization interfaces. You can assume a good amount based on the nature of the data:
If there are 5 rows of data in a table, and it’s not a helper table, then it’s probably enough to just have a page for each row and be done with it. If there are 5,000 rows, on the other hand, it probably makes sense to have a complete faceted browsing interface, as well as a general text search input.
If there are 10 columns, then, assuming you have a page showing all the information for any one row of data, you can just display all the values on that one page, in a vertical list. But if you have 100 columns, including information from auxiliary tables, then it probably makes sense to break up the page, using tabs or “children” pages or just creative formatting (small fonts, use of alternating colors, etc.)
If a map has over, say, 200 points, then it should probably be displayed as a “heat map”, or a “cluster map”, or maps should only show up after the user has already done some filtering.
If the date field in question has a range of values spread out over a few days, then just showing a list of items for each day makes sense. If it’s spread out over a few years, then a monthly calendar interface makes sense. And if it’s spread out over centuries, then a timeline makes sense.
Somehow software never makes these kinds of assumptions.
I am guilty of that myself, by the way. My MediaWiki extension Semantic Drilldown lets you define a drill-down interface for a table of data, just by specifying a filter/facet for every column (or, in Semantic MediaWiki’s parlance, property) of data that you want filterable. So far, so good. But Semantic Drilldown doesn’t look at the data to try to figure out the most reasonable display. If a property/column has 500 different values, then a user who goes to the drilldown page (at Special:BrowseData) will see 500 different values for that filter that they can click on. (And yes, that has happened.) That’s an interface failure: either (a) those values should get aggregated into a much smaller number of values; or (b) there should be a cutoff, so that any value that appears in less than, say, three pages should just get grouped into “Other”; or (c) there should just be a text input there (ideally, with autocompletion), instead of a set of links, so that users can just enter the text they’re looking for; or… something. Showing a gigantic list of values does not seem like the ideal approach.
Similarly, for properties that are numbers, Semantic Drilldown lets you define a set of ranges for users to click on: it could be something like 0-49, 50-199, 200-499 and so on. But even if this set of ranges is well-calibrated when the wiki is first set up, it could become unbalanced as more data gets added – for example, a lot of new data could be added, that all has a value for that property in the 0-49 range. So why not have the software itself set the appropriate ranges, based on the set of data?
And maybe the number ranges should themselves shift, as the user selects values for other filters? That’s rarely done in interfaces right now, but maybe there’s an argument to be made for doing it that way. At the very least, having intelligent software that is aware of the data it’s handling opens up those kinds of dynamic possibilities for the interface.
Mobile and the rest
Another factor that should get considered (and is also more important than the underlying subject matter) is the type of display. So far I’ve described everything in terms of standard websites, but you may want to display the data on a cell phone (via either an app or a customized web display), or on a tablet, or on a giant touch-screen kiosk, or even in a printed document. Each type of display should ideally have its own handling. For someone creating a website from scratch, that sort of thing can be a major headache – especially the mobile-friendly interface – but a generic data application could provide a reasonable default behavior for each display type.
By the way, I haven’t mentioned desktop software yet, but everything that I wrote before, about software serving as a wrapper around a database, is true of a lot of enterprise desktop software as well – especially the kind meant to hold a specific type of data: software for managing hospitals, amusement parks, car dealerships, etc. So it’s quite possible that an approach like this could be useful for creating desktop software.
Current solutions
Is there software (web, desktop or otherwise) that already does this? At the moment, I don’t know of anything that even comes close. There’s software that lets you define a data structure, either in whole or in part, and create an interface apparatus around it of form fields, drill-down, and other data visualizations. I actually think the software that’s the furthest along in that respect is the Semantic MediaWiki family of MediaWiki extensions, which provide enormous amounts of functionality around an arbitrary data structure. There’s the previously-mentioned Semantic Drilldown, as well as functionality that provides editing forms, maps, calendars, charts etc. around an arbitrary set of data. There are other applications that do some similar things – like other wiki software, and like Drupal, which lets you create custom data-entry forms, and even like Microsoft Access – but I think they all currently fall short of what SMW provides, in terms of both out-of-the-box functionality and ease of use for non-programmers. I could be wrong about that – if there’s some software I’m not aware of that does all of that, please let me know.
Anyway, even if Semantic MediaWiki is anywhere near the state of the art, it still is not a complete solution. There are areas where it could be smarter about displaying the data, as I noted before, and it has no special handling for mobile devices; but much more importantly than either of those, it doesn’t provide a good solution for data that doesn’t already live in the wiki. Perhaps all the world’s data should be stored in Semantic MediaWiki (who am I to argue otherwise?), but that will never be the case.
Now, SMW actually does provide a way to handle outside data, via the External Data extension – you can bring in data from a variety of other sources, store it in the same way as local data, and then query/visualize/etc. all of this disparate data together. I even know of some cases where all, or nearly all, of an SMW-based wiki’s data comes from externally – the wiki is used only to store its own copy of the data, which it can then display with all of its out-of-the-box functionality like maps, calendars, bulleted lists, etc.
But that, of course, is a hack – an entire wiki apparatus around a set of data that users can’t edit – and the fact that this hack is in use just indicates the lack of other options currently available. There is no software that says, “give me your data – in any standard format – and I will construct a pleasant display interface around it”. Why not? It should be doable. Data is data, and if we can make reasonable assumptions based on its size and nature, then we can come up with a reasonable way to display it, without requiring a programmer for it.
Bringing in multiple sources
And like SMW and its use of the External Data extension, there’s no reason that the data all has to come from one place. Why can’t one table come from a spreadsheet, and another from a database? Or why can’t the data come from two different databases? If the application can just use its own internal database for the data that it needs, there’s no limit to how many sources it was originally stored in.
And that also goes for public APIs, that provide general information that can enrich the local information one has. There are a large and growing number of general-information APIs, and the biggest one by far is yet to come: Wikidata, which will hold a queriable store of millions of facts. How many database-centered applications could benefit from additional information like the population of a city, the genre of a movie, the flag of a country (for display purposes) and so on? Probably a fair number. And a truly data-neutral application could display all such information seamlessly to the user – so there wouldn’t be any way of knowing that some information originally came from Wikidata as opposed to having been entered by hand by that site’s own creators or users.
Data is data. It shouldn’t be too hard for software to understand that, and it would be nice if it did.
If you use Semantic MediaWiki, or are curious about it, I highly recommend going to SMWCon, the twice-yearly conference about Semantic MediaWiki. The next one will be a month and half from now, in New York City – the conference page is here. I will be there, as will Jeroen De Dauw, who will be representing both core SMW developers and the extremely important Wikidata project; as will a host of SMW users from corporations, the US government, startups and academia. There will be a lot of interesting talks, the entrance fee is quite reasonable ($155 for a three-day event), and I’m the local chair, so I can tell you for sure that there will be some great evening events planned. (And the main conference will be at the hacker mecca ITP, which is itself a cool spot to check out if you’ve never been there.) I hope some of you can make it!
I am happy to announce a project I’ve been working on for a rather long time now: Working with MediaWiki, a general-purpose guide to MediaWiki. It finally was released officially two days ago. It’s available in print-on-demand (where it numbers roughly 300 pages), e-book (.epub and .mobi formats) and PDF form.
As anyone who knows WikiWorks and our interests might expect, Semantic MediaWiki and its related extensions get a heavy focus in the book: a little less than one third of the book is about the Semantic MediaWiki-based extensions. I think that’s generally a good ratio: anyone who wants to learn about Semantic MediaWiki can get a solid understanding of it, both conceptually and in practice; while people who don’t plan to use it still get a lot of content about just about every aspect of MediaWiki.
This book is, in a sense, an extension of our consulting business, because there’s a lot of information and advice contained there that draws directly on my and others’ experience setting up and improving MediaWiki installations for out clients. There’s a section about enabling multiple languages on the same wiki, for instance, which is a topic I’ve come to know fairly well because that’s a rather common request among clients. The same goes for controlling read- and write-access. Conversely, there is only a little information devoted to extensions that enable chat rooms within wikis, even though there are a fair number of them, because clients have never asked about installing chat stuff.
So having this book is like having access to our consultants, although of course at a lower price and with all the benefits of the written word. (And plenty of illustrations.) And I think it’s a good investment even for organizations that do work with us, to get the standard stuff out of the way so that, when it comes time to do consulting, we can focus on the challenging and unique stuff.
Once again, here is the book site: Working with MediaWiki. I do hope that everyone who’s interested in MediaWiki checks it out – my hope is that it could make using MediaWiki simpler for a lot of people.
Today is the launch date of a new WikiWorks site: Innovention wiki, which “showcases the themes of innovation and invention through stories drawn from South Australia.”
Skinning
We were able to design a really nice skin for the site, based on the specs of their designer. It uses a 3-column layout which is kind of uncharted territory as far as MediaWiki skins go. Part of the challenge here was the right-hand column. The search section is a part of the skin, while the maps, photos and videos are generated by the MediaWiki page itself. This was accomplished by putting that stuff into a div which uses absolute positioning.
Another challenge was trying to fit a decent form into a very narrow middle column. The solution was to hide the right column via CSS, since the search form doesn’t really need to be on a form page. Then, the middle column is stretched to cover both columns. This was easy to do, since Semantic Forms helpfully adds a class to the body tag for any formedit page (which works for existing pages) and MediaWiki adds a tag to any Special page (for when adding a new place with Special:FormEdit). So the content area was accessed with:
.action-formedit #content, .mw-special-FormEdit #content {
width: (a whole lot);}
Displaying different stuff to logged in and anonymous users
While on the topic of body attributes, MediaWiki does not add any classes to the body tag which would differentiate logged in from anonymous users. This doesn’t present a problem for the skin, which can easily check if the user is logged in. But what if you wanted to have a part of the MediaWiki content page displayed only for anonymous users? A common example would be exhortations to create an account and/or sign in. That’s something that should be hidden for logged in users. Fortunately, this is easily and cleanly resolved.
Since this was a custom skin, we overrode the Skin class’s handy addToBodyAttributes function (hat tip):
function addToBodyAttributes( $out, $sk, &$bodyAttrs ) {
$bodyClasses = array();
/* Extend the body element by a class that tells whether the user is
logged in or not */
if ( $sk->getUser()->isLoggedin() ) {
$bodyClasses[] = 'isloggedin';
} else {
$bodyClasses[] = 'notloggedin';
}
if ( isset( $bodyAttrs['class'] ) && strlen( $bodyAttrs['class'] ) > 0 ) {
$bodyAttrs['class'] .= ' ' . implode( ' ', $bodyClasses );
} else {
$bodyAttrs['class'] = implode( ' ', $bodyClasses );
}
return true;
}
For the built in skins, this is still easy to do. Just use the same code with the OutputPageBodyAttributes hook in your LocalSettings.php. This function adds a class to the body tag called either “isloggedin” or “notloggedin.” Then add the following CSS to your MediaWiki:SkinName.css:
Now in your MediaWiki code simply use these two classes to hide information from anonymous or logged in users. For example:
<span class="hideifnotloggedin">You're logged in, mate!</span>
<span class="hideifloggedin">Dude, you should really make an account.</span>
Combine with some nifty login and formedit links
Or even better, here’s a trick to generate links to edit the current page with a form:
<span class="hideifnotloggedin"> [{{fullurl:{{FULLPAGENAMEE}}|action=formedit}} Edit this page]</span>
…and a bonus trick that will log in an anonymous user and THEN bring him to the form edit page:
<span class="hideifloggedin">[{{fullurl:Special:Userlogin|returnto={{FULLPAGENAMEE}}&returntoquery=action=formedit}} Log in and edit this page.]</span>
It doesn’t get much better than that! See it in action here. Yes, you’d have to make an account to really see it work. So take my word for it.
Spam bots
While on the subject of making an account, it seems that bots have gotten way too sophisticated. One of our clients had been using ConfirmEdit with reCAPTCHA and was getting absolutely clobbered by spam. I’ve found that for low traffic wikis, the best and easiest solution is to combine with QuestyCaptcha instead. They’re easily broken by an attacker who is specifically targeting that wiki, but very few wikis have gained that level of prominence. The trick is to ask a question that only a human can answer. I’ve had success with this type of question:
Please write the word, “horsse”, here (leave out the extra “s”): ______
Featured article slideshow
This site has a pretty cool main page. The main contributor to that coolness is the transitioning slideshow with various featured articles. Gone are the days when a wiki only featured one page! This was made possible by bringing the Javascript Slideshow extension up to date, which was done by our founder Yaron Koren in honor of Innovention wiki. The articles are inserted manually which gives the user complete control over the appearance. But it would be pretty simple to generate the featured pages with a Semantic MediaWiki query.
I regret to say that our consultant Jeroen De Dauw will not be doing any significant work for WikiWorks for at least the next year. Thankfully, that’s for a very good reason: he’s moved to Berlin to be part of the Wikidata project, which starts tomorrow.
Wikidata is headed by Denny Vrandecic, who, like Jeroen, is a friend and colleague of mine; and its goal is to bring true data to Wikipedia, in part via Semantic MediaWiki. There was a press release about it on Friday that got some significant media attention, including this good summary at TechCrunch.
I’m very excited about the project, as a MediaWiki and SMW developer, as a data enthusiast, and simply as a Wikipedia user. This project quite different from any of the work that I’ve personally been involved with, because Wikipedia is simply a different beast from any standard wiki. There are five challenges that are specific to Wikipedia: it’s massive, it needs to be extremely fast at all times, it’s highly multi-lingual (over 200 languages currently), it requires references for all facts (at least in theory), and it has, at this point, no real top-down structure.
So the approach they will take will be not to tag information within articles themselves, the way it’s done in Semantic MediaWiki, but rather to create a new, separate site: a “Data Commons”, where potentially hundreds of millions of facts (or more?) will be stored, each fact with its own reference. Then, each individual language Wikipedia can make use of those facts within its own infobox template, where that Wikipedia’s community sees fit to use it.
It’s a bold vision, and there will be a lot of work necessary to pull it off, but I have a lot of faith in the abilities of the programmers who are on the team now. Just as importantly, I see the planned outcome of Wikidata as an inevitable one for Wikipedia. Wikipedia has been incrementally evolving from a random collection of articles to a true database since the beginning, and I think this is a natural step along that process.
A set of files were discovered in 2010 that represented the state of Wikipedia after about six weeks of existence, in February 2001. If you look through those pages, you can see nearly total chaos: there’s not even a hint of a unifying structure, or guidelines as to what should constitute a Wikipedia page; over 10% the articles related in some way to the book Atlas Shrugged, presumably added by a devoted fan.
11 years later, there’s structure everywhere: infobox templates dictate the important summary information for any one subject type, reference templates specify how references should be structured, article-tagging templates let users state precisely the areas they think need improvement. There are guidelines for the first sentence, for the introductory paragraphs (ideally, one to four of them, depending on the article’s overall length), for how detailed sections should be, for when one should link to years, and so on. There are also tens of thousands of categories (at least, on the English-language Wikipedia), with guidelines on how to use them, creating a large set of hierarchies for browsing through all the information. These are all, in my eyes, symptoms of a natural progression toward a database-like system. Why is it natural? Because, if a rule makes sense for one article, it probably makes sense for all of them. Of course, that’s not always true, and there can be sub-rules, exceptions, etc.; but still, there’s no use reinventing the wheel for every article.
People complain that the proliferation of rules and guidelines, not to mention categories and templates, drive away new users, who are increasingly afraid to edit articles for fear of doing the wrong thing. And they’re right. But the solution to this problem is not to scale back all these rules, but rather to make the software more aware of the rules, and the overall structure, to prevent users from being able to make a mistake in the first place. That, at heart, was the thinking behind my extension Semantic Forms: if there’s a specific way of creating calls to a specific template, there’s no point requiring each user to create them in that way, when you can just display a form, let the user only enter valid inputs, and have the software take care of the rest.
Now, Wikidata isn’t concerned with the structuring of articles, but only with the data that they contain; but the core philosophy is the same: let the software take care of anything that there’s only one right way to do. If a country has a certain population (at least, according to some source), then there’s no reason that the users of every different language Wikipedia need to independently look up and maintain that information. If every page about a mutiplanetary system already has its information stored semantically, then there’s no reason to separately maintain a hand-generated list of multiplanetary systems. And if, for every page about a musician, there’s already semantic information about their genre, instrument and nationality, then there’s no reason for categories such as “Danish jazz trumpeters“. (And there’s probably much less of a need for categories in general.)
With increased meaning/semantics on one hand, and increased structure on the other, Wikipedia will become more like a database that can be queried, than like a standard encyclopedia. And at that point, the possibilities are endless, as they say. The demand is already there; all that’s missing is the software, and that’s what they’ll be working on in Berlin. Viel Glück!
This is something that comes up, particularly when dealing with MediaWiki infoboxes. We had an infobox table floating on the right side of the page with a fixed with. Then there was an image to the left of it that was supposed to take up the remaining page’s width. The challenge was: What happens as the user shrinks or stretches the browser window? The fixed width table would stay the same size but the image would have to grow or shrink with the browser width.
There are some scripts out there that would do this. You don’t need them. Here’s what to do:
Simple, right? Basically, the 100% width combined with the right margin gives us a “100% percent minus x number of pixels” effect. The browser responds accordingly.





.jpg)








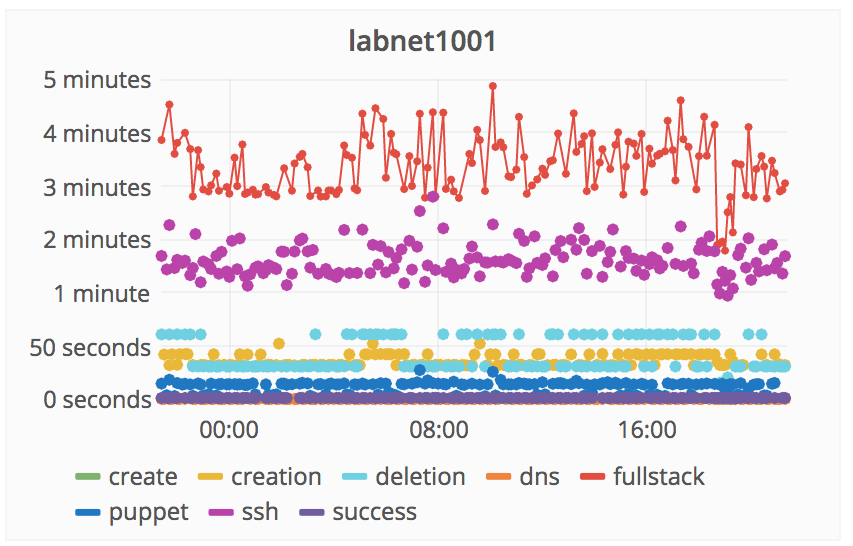
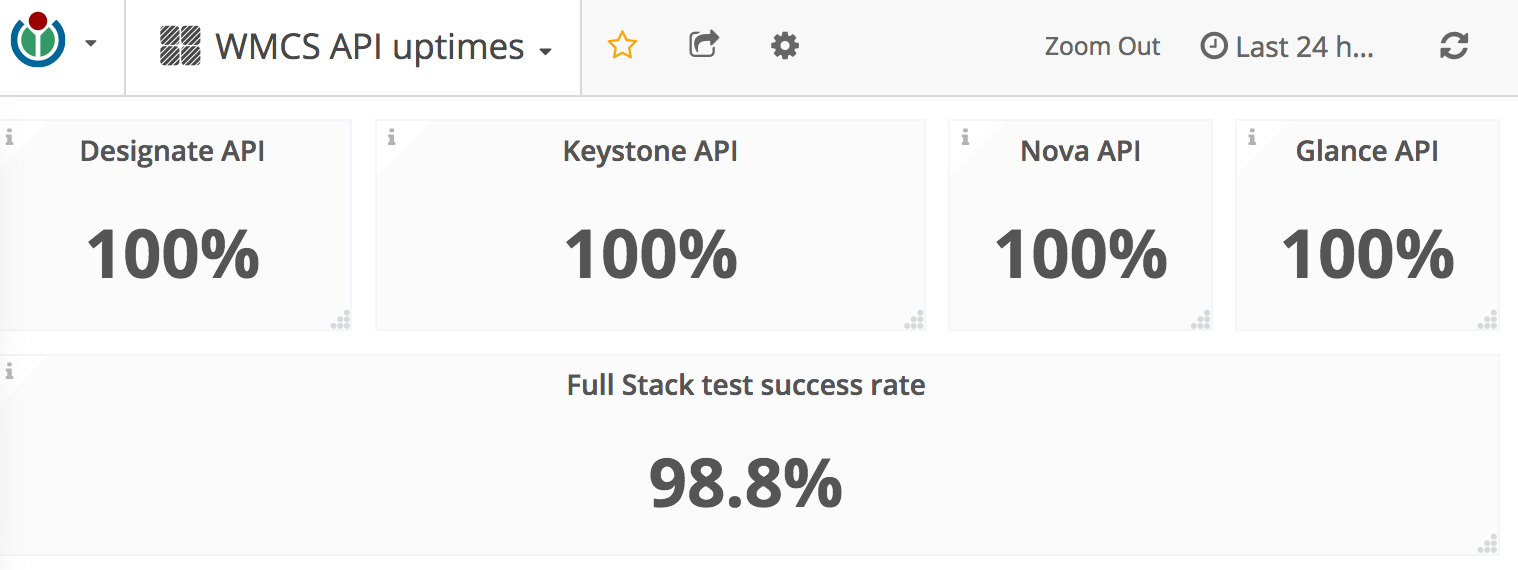






 English is written left to right. Hebrew is written right to left. We know that. Browsers (for the most part) know that too, just like they know that the default directionality of a web page is left-to-right (LTR), and that if there is a setting that explicitly defines the direction to right-to-left, the page should flip like a mirror. Browsers are smart like that. Mostly.
English is written left to right. Hebrew is written right to left. We know that. Browsers (for the most part) know that too, just like they know that the default directionality of a web page is left-to-right (LTR), and that if there is a setting that explicitly defines the direction to right-to-left, the page should flip like a mirror. Browsers are smart like that. Mostly.








{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}